
XPS samples
A couple of readers answered my call for samples in diary entry "Analyzing XPS files", thanks!
Their samples are exactly of the same type (containing a phishing link), you can use the same commands I used in my previous diary entry to extract the URL:
Someone asked me to explain in more detail this one-liner I used in my last diary entry.
The problem: we want to extract the URLs from the XPS file.
The solution: the URLs are found in XML files inside a ZIP container (that's essentially the structure of an XPS file), hence, extract the files and grep for URLs.
Now, because of my IT formative years with Unix, I have a preference for command-line tools piped together. That's what I use in this one-liner.
First we need the content of the ZIP file (e.g. XPS file). We can get this with unzip, but then the content gets written to disk, and I want to avoid this, I want to send all the output to stdout, so that it can be piped into the next command, that will extract the URLs. When I analyze malware, I try to write to disk as little as possible.
This can be done with my tool zipdump.py.
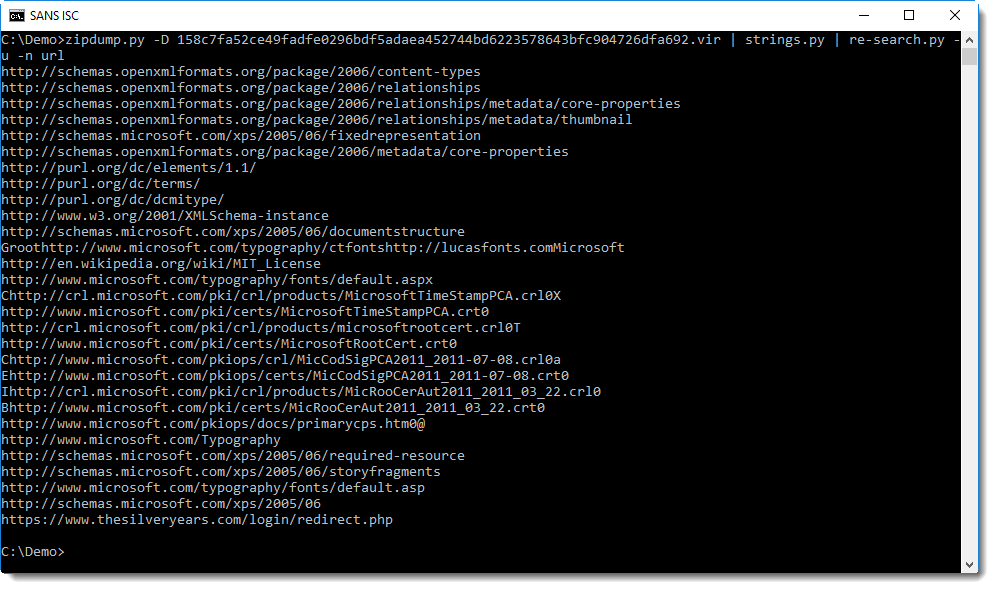
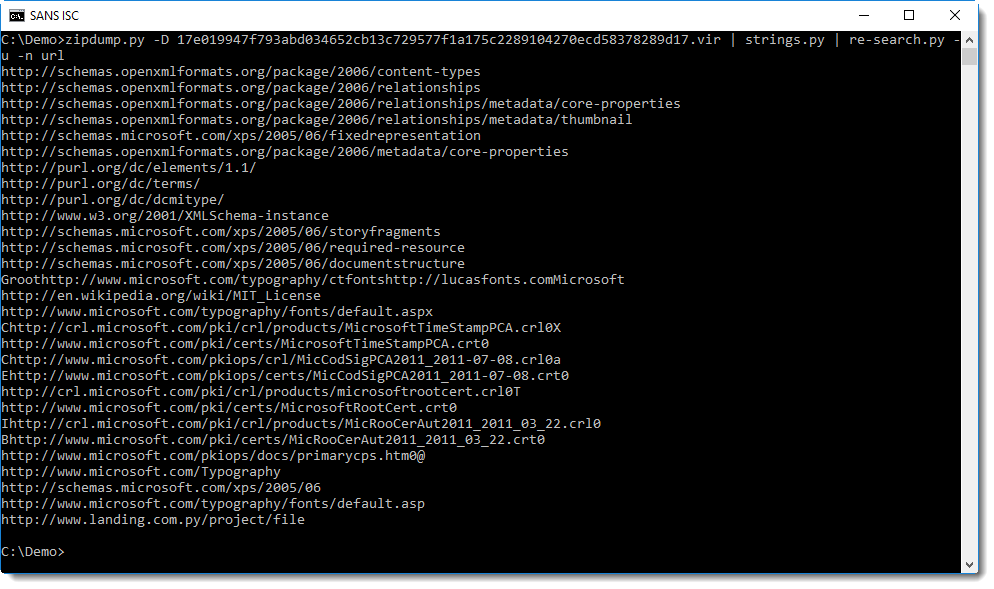
Command "zipdump.py -D 17e019947f793abd034652cb13c729577f1a175c2289104270ecd58378289d17.vir" decompresses all files in this XPS sample, and outputs the bytes to stdout: option -D dumps the content of all files inside the ZIP archive.
Then we want to grep for the URLs. We don't know what domains we need to look for, so we will use a regular expression that matches generic URLs. We could do this with grep, but that regular expression for URLs is quite long, and I don't have it memorized. That's one of the reasons I developed my re-search.py tool: it has a small library of regular expressions.
Command "re-search.py -n url" greps for URLs. Option -n instructs re-search.py to look up a regular expression in its library by name, the name of the regex we want is url.
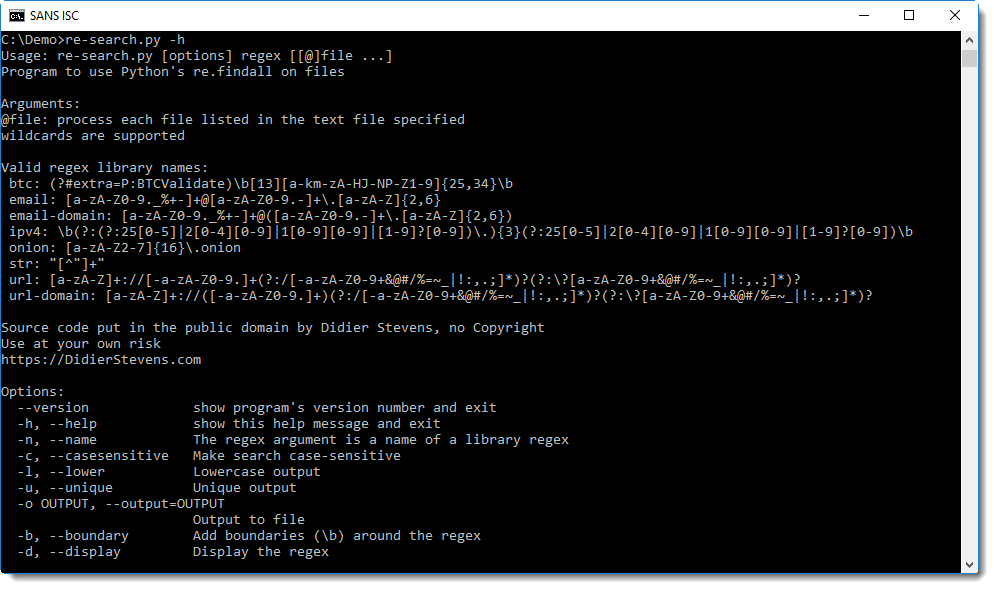
With help option -h, you can get an overview of re-search's regex library (there's also a build-in man page, option -m displays this man page):
Microsoft documents (like OOXML Office documents and XPS documents) contain many URLs, identifying the different standards and formats used in said document: grepping for URLs will give a long list. To make this list shorter, I used option -u (unique) to report each URL only once, regardless of the numbers of times each URL appears in the contained files. The complete re-search command we will use is "re-search.py -u -n url".
We can pipe commands zipdump and re-search together, but then we risk encountering problems, because most of the time XPS documents will contain non-ASCII files, like images and UNICODE files. re-search.py can handle binary files (like images) given the right option, but it does not handle UNICODE properly (yet).
That's why we use command strings to extract all strings from the files inside the ZIP archive. Unfortunately, Microsoft Sysinternals' strings.exe command does not accept input from stdin. That's why I use my own version that does: strings.py.
Thus the complete chain of commands becomes:
zipdump.py -D 17e019947f793abd034652cb13c729577f1a175c2289104270ecd58378289d17.vir | strings.py | re-search.py -u -n url
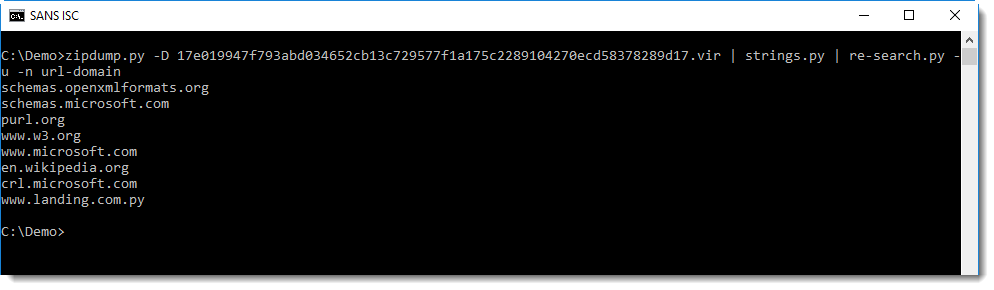
If you still have difficulties finding the phishing URL in this long list of URLs, you can use regular expression url-domain. This regular expression matches URLs exactly like regular expression url, but only outputs the domain, and not the full URL.
Strictly speaking, re-search.py is more like grep with option -o. grep -o does not output the complete line in case of a match, but just the match itself. This is what re-search.py does by default.
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com


Comments