
Getting some intelligence from malspam
Many of us are receiving a lot of malspam every day. By "malspam", I mean spam messages that contain a malicious document. This is one of the classic infection vectors today and aggressive campaigns are started every week. Usually, most of them are blocked by modern antivirus or anti-spam but these files could help us to get some intelligence about the topic used by attackers to fool their victims. By checking the names of malicious files (often .rar, .gip or .7r archives), we found classic words like ‘invoice’, ‘reminder’, ‘urgent’, etc… From an attacker perspective, choosing the right name can increase the chances that the target will open the file by business needs or just…curiosity!
I collected files attached to malicious emails and tried to categorize them to determine what were the most common names. To achieve this, I created a list of simple regular expressions based on classic strings and assigned a category to them. Both are stored in a CSV files:
Regex,Category <redacted>,Targeted <redacted>,Targeted .*inv[oi]ce.*,Commercial .*facture.*,Commercial inv.*,Commercial .*RF[QP].*,Commercial .*order.*,Commercial .*po.*,Commercial .*quotation.*,Commercial .*purchas.*,Commercial .*voucher.*,Commercial .*payment.*,Financial_Services .*slip.*,Financial_Services .*ban(k|que).*,Financial_Services .*swift.*,Financial_Services .*(HSBC).*,Financial_Services .*remitance.*,Financial_Services .*wire.*,Financial_Services .*IDBI.*,Financial_Services .*fraud.*,Financial_Services .*loan.*,Financial_Services .*paypal.*,Internet_Services .*dropbox.*,Internet_Services .*microsoft.*,Internet_Services .*apple.*,Internet_Services .*(DHL|UPS|TNT).*,Delivery_Services .*parcel.*,Delivery_Services .*shipping.*,Delivery_Services .*packet.*,Delivery_Services .*fax.*,Communication_Services .*mfp.*,Communication_Services .*voice.*,Communication_Services .*scan.*,Communication_Services .*email.*,Communication_Services .*resume.*,Business_Services .*cv.*,Business_Services .*contract.*,Business_Services .*letter.*,Business_Services .*account.*,Business_Services .*confirmation.*,Business_Services .*confidential.*,Sensitive_Documents .*crypted.*,Sensitive_Documents .*urgent.*,Sensitive_Documents .*secure.*,Sensitive_Documents .*protected.*,Sensitive_Documents \d+\.\s+,Numeric_Documents .*booking.*,Booking_Services .*photo.*,Media_Services .*video.*,Media_Services .*pic.*,Media_Services .*foto.*,Media_Services pdf.*,Media_Services img.*,Media_Services IMG.*,Media_Services
(Note that the two first lines have been obfuscated because they are related to really targeted attacks against an organization)
Then I built a list of 94387 filenames based on the data that I collected since the beginning of 2017. The best place to collect those data is on your incoming mail server or any anti-spam, anti-malware solution logfiles. This is a good opportunity to remind you that logs are critical, log as much as possible! How to check the filenames against all the regular expressions above and tag them with the second field ('Category'). To perform this in an efficient way, I used Splunk.
The regular expressions are stored in the ‘maldocs_re.csv’ file and the filenames into ‘maldocs.csv’ and the following query will return interesting statistics:
|inputlookup maldocs.csv |eval count=0 |join max=0 count [| inputlookup maldoc_re.csv | eval count=0] |eval test=if(match(filePath, Regex),1,0) |where test=1 |stats count by Category
After a few seconds or minutes later, depending on the amount of data you have to process, you will get a nice graph like this:
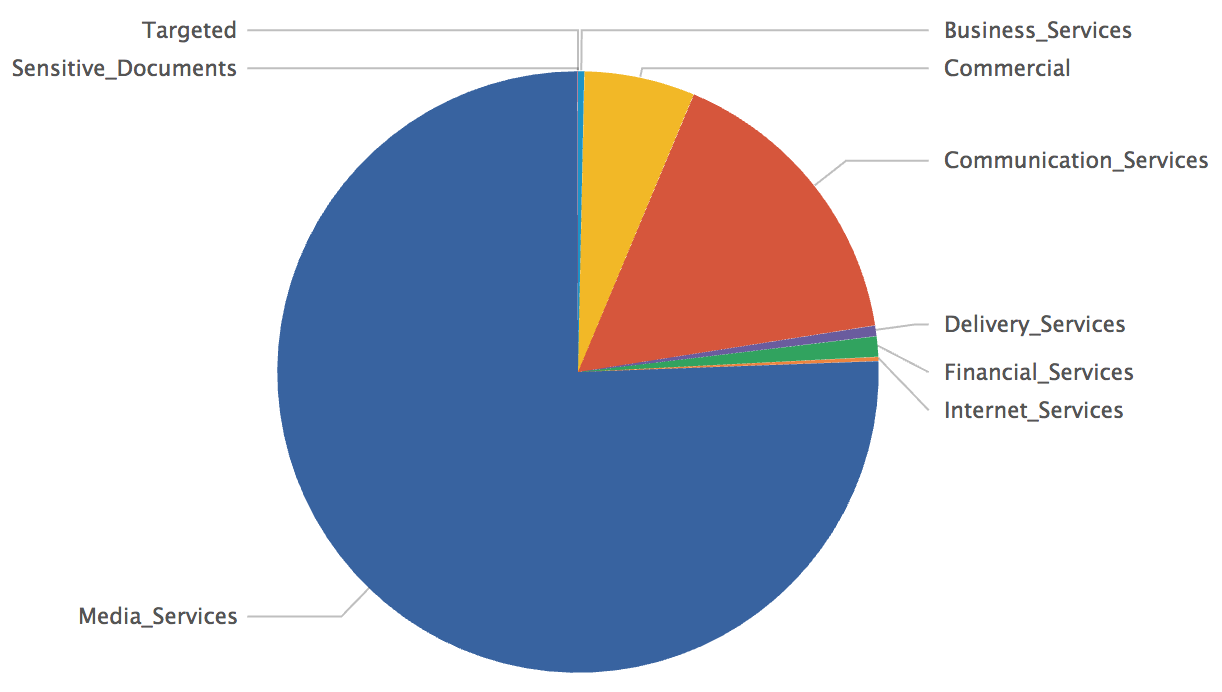
You can see that most of the malicious files are based on media files but that we also have some hits against the 'Targeted' category. It would be worth to have a look at them! Finally, if you define a single category called ‘Targeted’ with good regular expressions matching your business activity, domain names, login formats, brands or whatever, you can generate alerts if such files are sent to your users and be aware of potential targeted attacks!
Happy hunting!
Xavier Mertens (@xme)
ISC Handler - Freelance Security Consultant
PGP Key
| Reverse-Engineering Malware: Advanced Code Analysis | Online | British Summer Time | Jul 28th - Aug 1st 2025 |


Comments
Anonymous
Sep 18th 2017
7 years ago
.*inv[oi]+ce.*
I added this one because I already saw some document with the typo 'invioce-xxx.doc'
Anonymous
Sep 18th 2017
7 years ago
Anonymous
Sep 18th 2017
7 years ago