Obfuscated MIME Files
As could be expected, the race to obfuscate MS Office documents stored as MIME files to bypass detection, would not stop with a simple extra line.
I was given a sample where the first two lines are not fields:
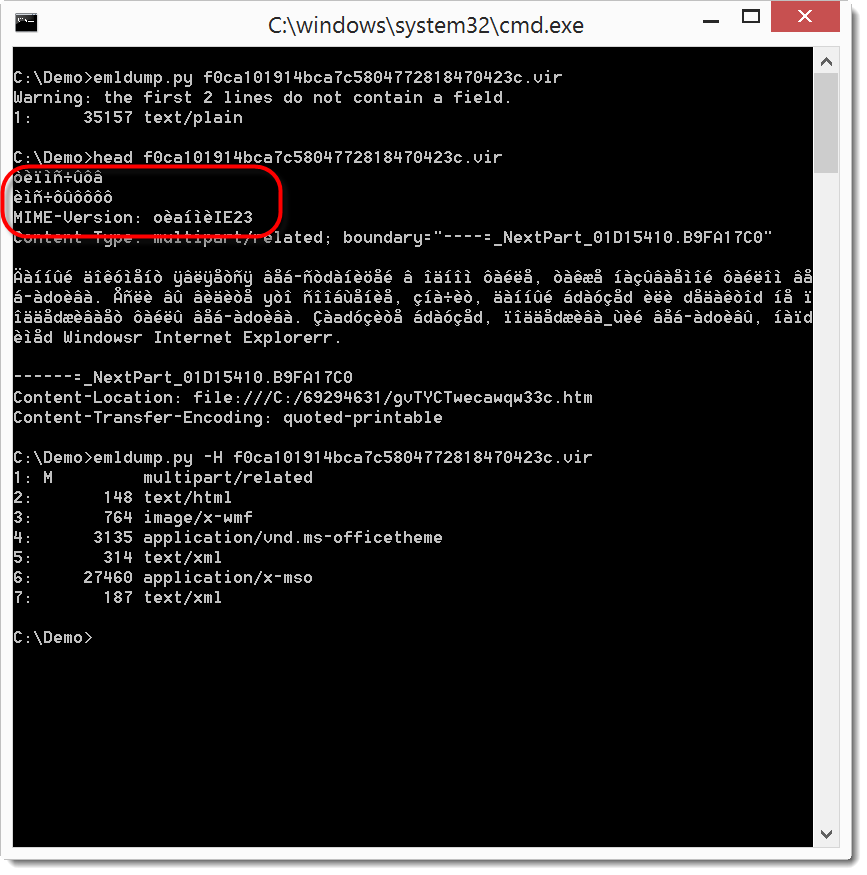
Notice that the MIME version is also not according to specs.
You can see that my emldump tool now issues a warning when you analyze such MIME files. My tool now scans the beginning of the file until it finds a field-name (as defined by RFC822). You can skip these extra, non-conforming lines with option -H.
We can now extract the MSO part and feed it to oledump. But as you can see in the screenshot, this fails. This is because the BASE64 encoding of the MSO file was also obfuscated: it starts with a line (njguiklnsa) that is not valid BASE64 encoding (the string length of njguiklnsa is not a multiple of 4).
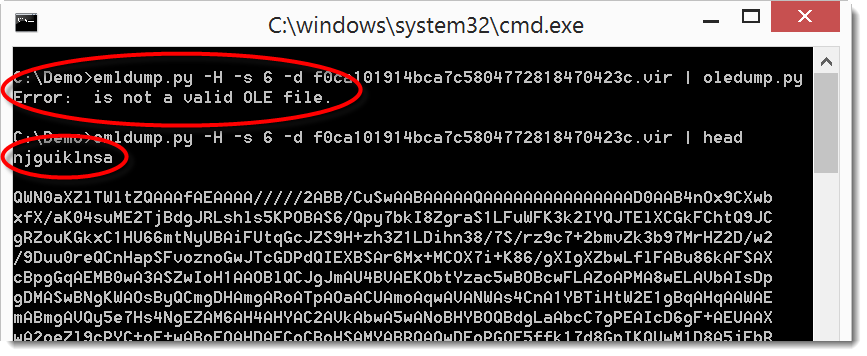
This throws off the MIME parsing module from Python I use in emldump. But it clearly doesn't throw off the MIME parser in MS Office.
So let's remove this string:
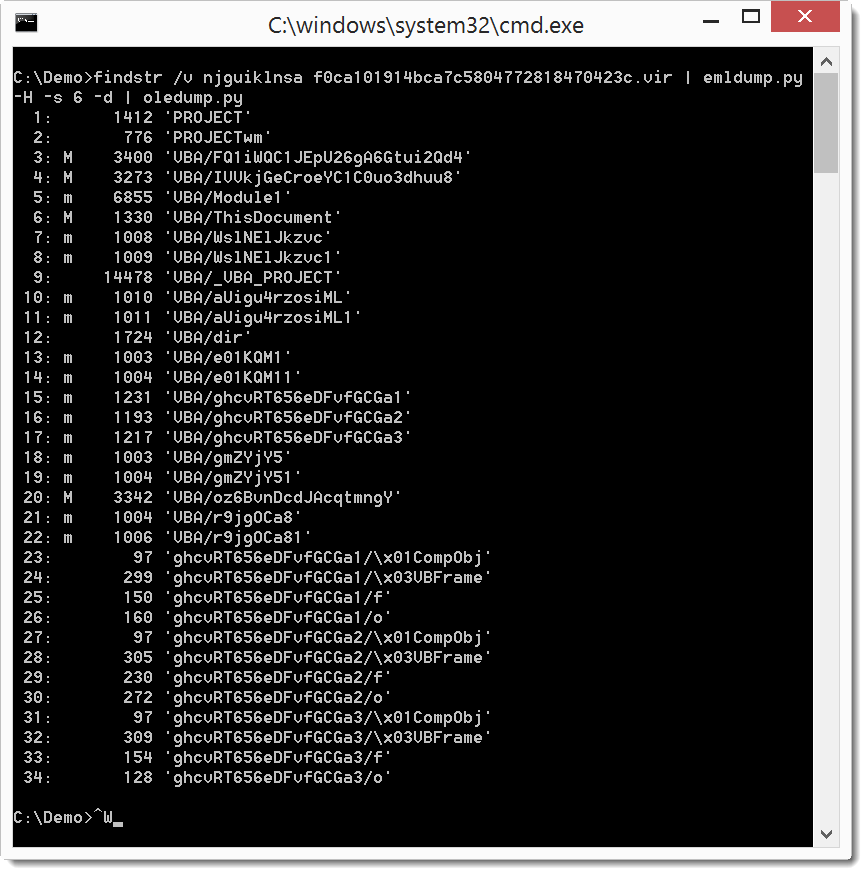
I use findstr's option v to filter out the string, on Linux and OSX I would use grep.
Didier Stevens
SANS ISC Handler
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com
IT Security consultant at Contraste Europe.


Comments