SNI5GECT: Sniffing and Injecting 5G Traffic Without Rogue Base Stations
As the world gradually adopts and transitions to using 5G for mobile, operational technology (OT), automation and Internet-of-Things (IoT) devices, a secure 5G network infrastructure remains critical. Recently, the Automated Systems SEcuriTy (ASSET) Research Group have released a new framework named SNI5GECT [pronounced as Sni-f-Gect (sniff + 5G + inject)] that enables users of the framework to i) sniff messages from pre-authentication 5G communication in real-time and ii) inject targeted attack payloads in downlink communications towards User Equipments (UE). I had previously written about how 5G connections are established over here, hence I will be diving directly into the SNI5GECT framework. In this diary, I will briefly provide an overview of the SNI5GECT framework and discuss a new multi-stage downgrade attack leveraging the SNI5GECT framework.
As mentioned earlier, SNI5GECT can sniff uplink (UL) and downlink (DL) 5G New Radio (NR) traffic over the air and inject downlink messages at the correct timing (i.e. after a specific protocol state) so the UE would accept the message in real-time. Such features allow SNI5GECT to fingerprint, perform denial-of-service, or downgrade attacks on targets requiring message injection under different communication states. Compared to prior state-of-the-art works, the SNI5GECT framework does not require rogue gNodeB (gNB) stations when executing over-the-air sniffing and stateful injections. The absence of a rogue gNB is significant as it reduces setup complexities while increasing stealth (e.g. avoiding rogue hardware detection mechanisms) since broadcast messages [Master Information Block (MIB) and System Information Block (SIB)] are not transmitted. With reference to Figure 1, the overview of SNI5GECT is illustrated.
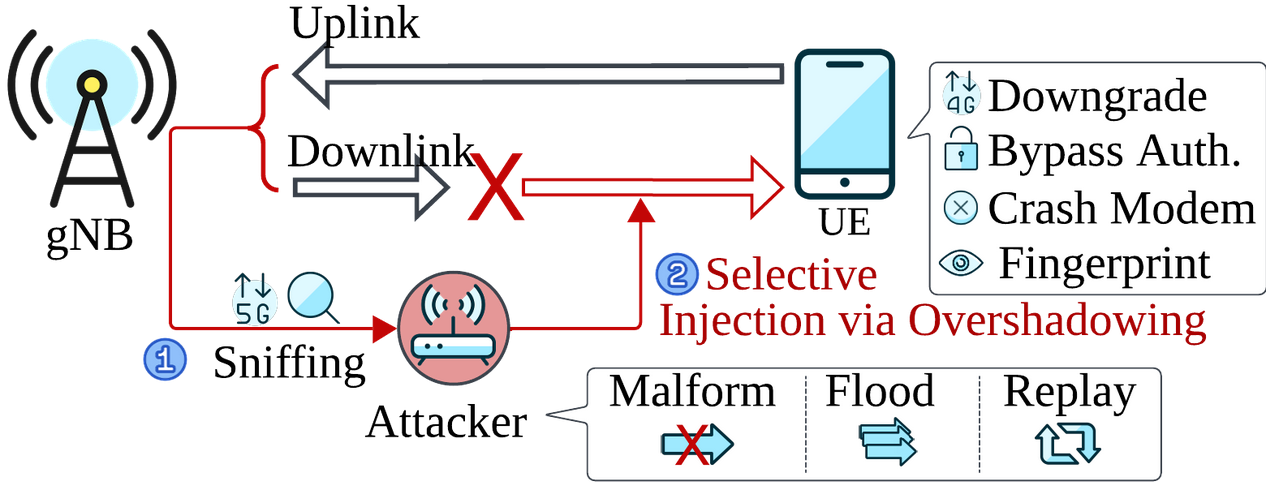
Figure 1: Overview of Capabilities in SNI5GECT (figure reproduced with permission from ASSET Research Group) [1]
SNI5GECT consists of the following components (also illustrated in Figure 2):
- Syncher: Synchronizes time and frequency with the target base station.
- Broadcast Worker: Decodes broadcast information such as SIB1 and detects and decodes Random Access Response (RAR) message.
- UETracker: Tracks the connection between the UE and the base station.
- UE DL Worker: Decodes messages sent from the base station to the UE.
- GNB UL Worker: Decodes messages sent from the UE to the base station.
- GNB DL Injector: Encodes and injects messages to the UE.
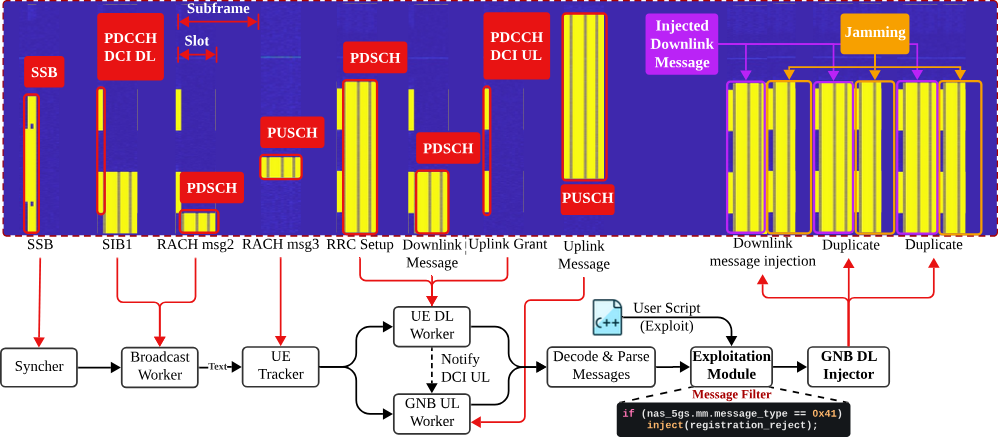
Figure 2: Components of SNI5GECT (figure reproduced with permission from ASSET Research Group) [1]
While the SNI5GECT framework has had a few modules integrated (e.g. 5Ghoul, Registration Reject, Fingerprinting, etc), I wanted to briefly highlight the new multi-stage downgrade attack (issued with CVD-2024-0096) that was discovered while SNI5GECT was being developed. Firstly, using SNI5GECT, a legitimate Authentication Request from the base station to the UE is captured. The Authentication Request message is replayed, albeit containing an invalid sequence number (SQN). According to the 3rd Generation Partnership Project (3GPP) specification, once the UE receives such replayed message, the UE replies with an Authentication Failure message, starts timer T3520 (a timer used in 5G mobile networks during the authentication and key agreement (AKA) procedure for emergency services) and denylists (i.e., mark as barred) the currently connected 5G gNB if the authentication procedure is not completed before expiry of such timer or the authentication procedure keeps failing. Once the UE denies the gNB and if no other gNB with a different set of configuration is around, it disconnects from 5G and connects to a nearby 4G eNB with the same Mobile Country Code (MCC) and Mobile Network Code (MNC) as the previously connected gNB instead. Furthermore, if no 4G eNBs are available, the UE does not attempt to connect to the same gNB even after waiting a long time. To prevent the gNB from retrying the authentication procedure, SNI5GECT injects the replayed Authentication Request message immediately after the Registration Request message. It continues to do so after receiving any Authentication Failure message from the UE. This forces the UE to drop the connection and denylist the gNB regardless of subsequent attempts from the gNB to continue with the authentication procedure.
There are some current limitations for the SNI5GECT framework. It currently only supports 5G and downlink injection, but can accept extensions as it has a modular design. The accuracy of sniffing and injection are affected by distance (and other factors like dense environments) between the device running SNI5GECT and the target UEs. SNI5GECT also cannot exploit any 5G post-authentication messages due to usage of encrypted messages by design. UEs that have had current connections (post-Random Access Response (RAR) state) with a gNB node would not have their traffic sniffed since SNI5GECT relies on tracking the UE’s Radio Network Temporary Identifier (RNTI) from the start of the Physical Random Access Channel (PRACH) procedure. Finally, SNI5GECT is unable to distinguish a smartphone model or user (i.e., victim UE) solely based on the RNTI to launch targeted attacks. Although it may appear that there are quite a number of limitations, there is currently no open-source alternatives that offer the capabilities that SNI5GECT present.
SNI5GECT can be used with Software Defined Radios (SDR) such as the USRP B210 SDR or USRP x310 SDR, and it is recommended that the host machine has minimally a 12-core CPU with 16GB of RAM. The full technical details of SNI5GECT can be found here [1], and also available as a downloadable PDF file [2].
References:
[1] https://www.sni5gect.com/
[2] https://www.usenix.org/system/files/usenixsecurity25-luo-shijie.pdf
-----------
Yee Ching Tok, Ph.D., ISC Handler
Personal Site
Mastodon
Twitter


Comments