Phishing ZIP With Malformed Filename
The output of my zipdump.py tool analyzing diary entry "Reader Malware: ZIP/HTML Phish" ZIP file is a bit strange:
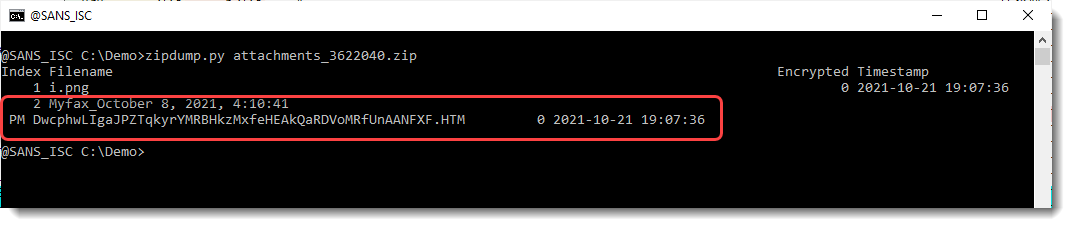
File 2 is spread over 2 lines: that's because it contains a carriage-return and a line-feed control character:
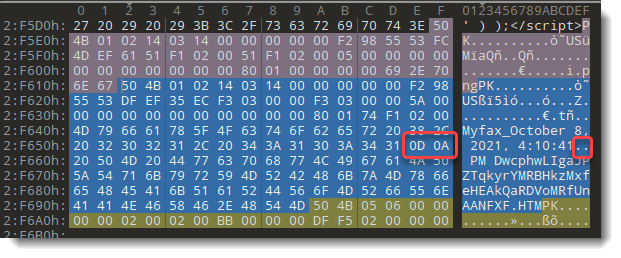
When I modify my zipdump tool to escape control characters, output looks like this:

I assumed that this malformed filename (filenames are not supposed to contain CR or NL characters) was a technique to mislead the user, e.g., that the user would not see the .html extension, because it was on another line.
But that is not the case. In Windows 10, without any installed archive utility, you don't even see the HTML file:
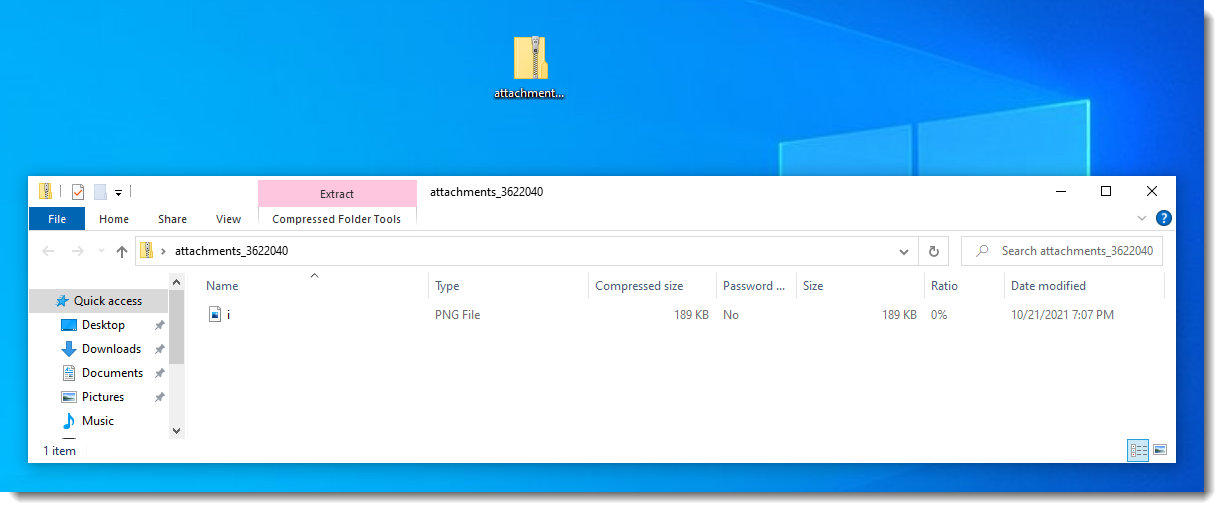
And you can view the PNG file (i.png), but not the HTML file:
Wit WinZIP you get a warning:
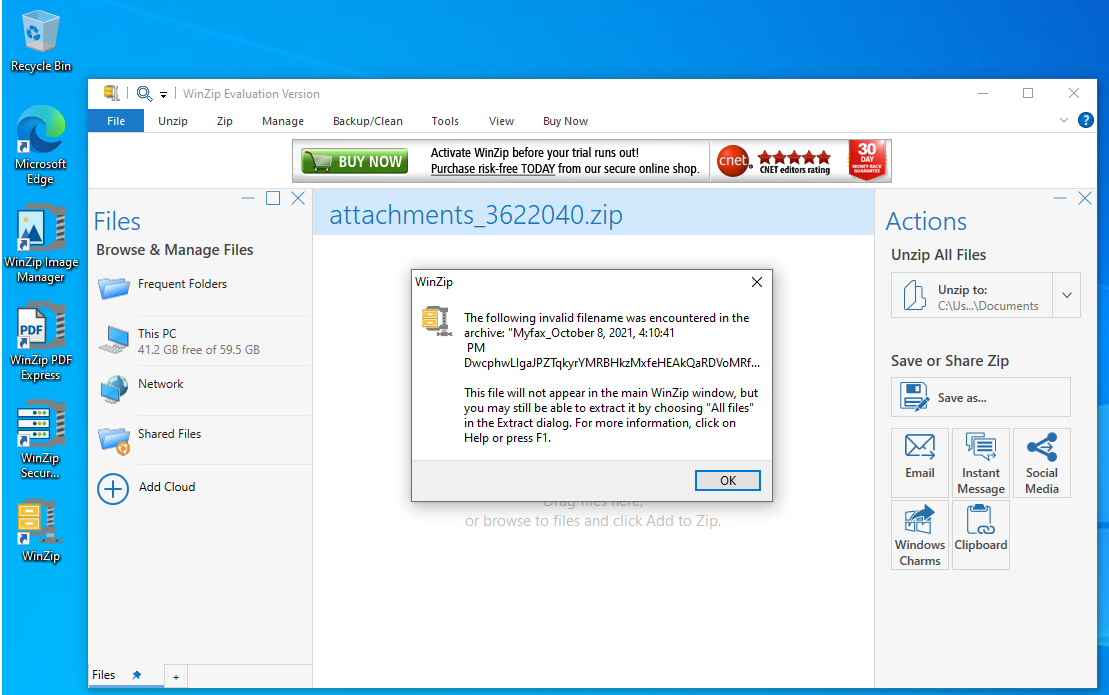
And the HTML file is not listed:
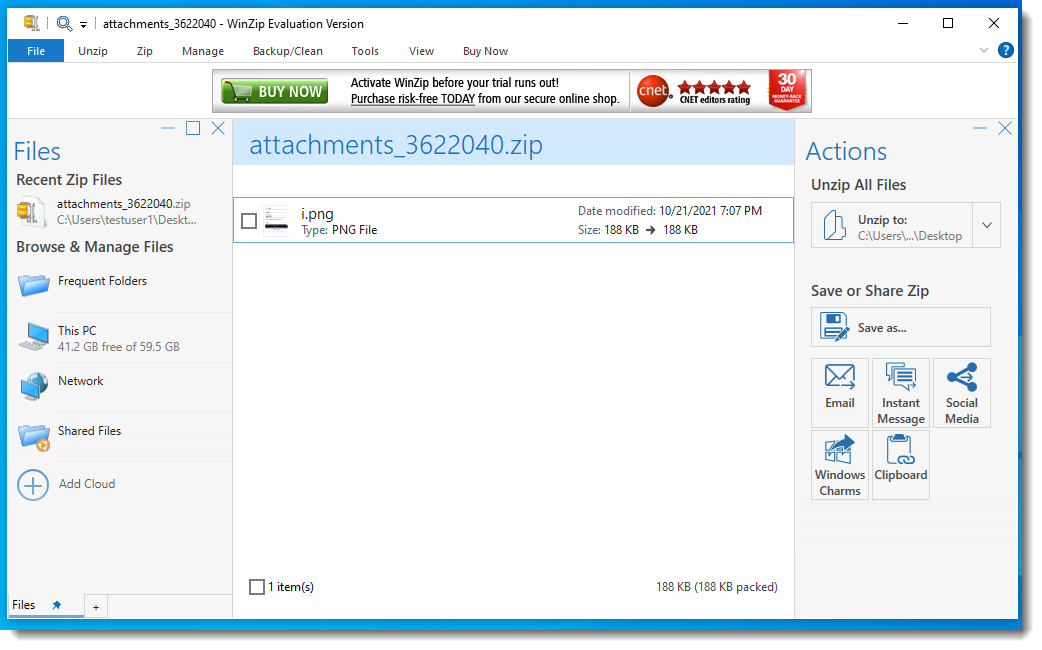
With WinRAR, you do see the HTML file:
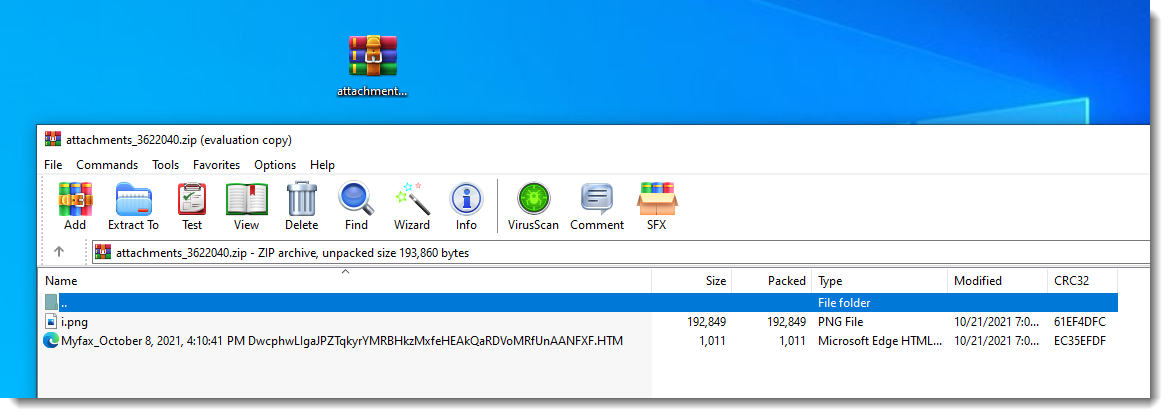
And also with 7-Zip:

Conclusion: depending on your archive utility, you might see the HTML file or not. But when you see the HTML file, you see the complete filename as if the CR and NL characters did not exist.
So the purpose of adding these special characters, is probably not to mislead the user.
I think that these characters are included, to bypass email detection systems that decompress archives to a temporary folder for scanning. Either the de-archiving utility might have issues with the CR and NL characters embedded in the filename, and just skip that file. Then it won't be scanned.
Or either the scanner might have issues dealing with the CR and NL characters embedded in the filename.
What do you think? Please post a comment with your hypothesis.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments