The Impact of Researchers on Our Data
Researchers have been using various tools to perform internet-wide scans for many years. Some will publish data continuously to either notify users of infected or misconfigured systems. Others will use the data to feed internal proprietary systems, or publish occasional research papers.
We have been offering a feed of IP addresses used by researchers. This feed is available via our API. To get the complete list, use:
https://isc.sans.edu/api/threatcategory/research
(add ?json or ?tab to get it in JSON or a tab delimited format)
We also have feeds for specific research groups (see https://isc.sans.edu/api ).
Some of the research groups I have seen recently:
- Shodan: Probably the best-known group. Shodan publishes the results of its scans at shodan.io.
- Shadowserver: Also relatively well known. Shadowserver doesn't make much of its data public. But it will make data available to ISPs to flag vulnerable/infected systems. You can find more about shadowserver at https://www.shadowserver.org/
- Strechoid: I just recently came across this group, and do not know much about them. They have a very minimal web page with an opt-out form: http://www.stretchoid.com/
- Onyphe: A company selling threat feeds. See https://www.onyphe.io/
- CyberGreen: See https://www.cybergreen.net/ . A bit like Shadowserver in that it is organized as a not-for-profit collaborative effort. Some data is made public, but more in aggregate form.
The next question: Should you block these IP addresses? Well... my simple honest answer: Probably not, but it all depends.
Shodan for example (I put them in the research category) will publish the data it collects, and an attacker may now use Shodan to find a vulnerable system instead of performing their own scan. There are anecdotal stories of that happening, and I have seen pentesters do this. But we had a SANS Technology Institute student perform some research to find the impact of Shodan and he did not find a significant change in attack traffic depending on if an IP was listed or not [1]. On the other hand, he also found that many IP addresses that appear to be used by Shodan are not identified as such via a reverse DNS lookup. Our list will likely miss a lot of them.
But then again, it probably doesn't hurt (right... our lists are "perfect"? Probably not). And blocking these scans at the perimeter may cut down on some of the noise.
So what is the impact? Here is some data I pulled from yesterday. We had a total of about 260k IP addresses reported to us. They generated about 30 million reports. So on average, a single source generates about 117 reports. The one Researcher exceeding this number significantly is Shodan, with about 5176 reports per source. Remember that Shodan will hit multiple target ports. Also, Shodan uses a relatively small set of published source IPs.
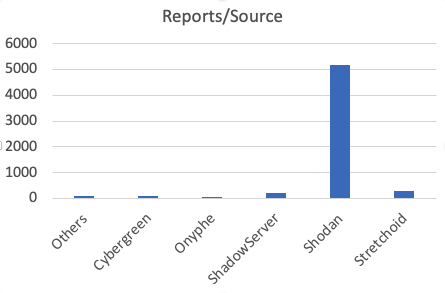
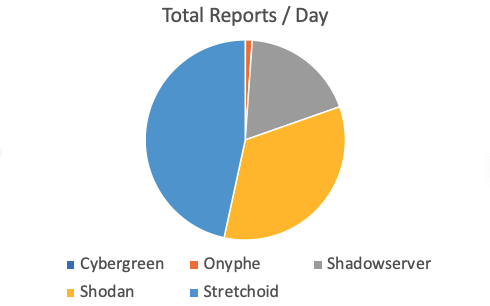
As far a the number of reports go, Stetchoid is actually the "winner" with Shodan 2nd and Shadowserver third. Cybergreen with a total of 100 reports (compared to Stretchoids 164k) hardly shows up. This may in part be due to us missing a lot of the Cybergreen addresses. I will have to look into that again.
What about the legality and ethics of these scans? The legality of port scans has often been discussed, and I am not a legal expert to weigh in on that. In my opinion, an ethical researcher should have a well-published "opt-out" option. IP addresses should reverse resolve to a hostname that will provide additional information about the organization performing the scan. Scans also should be careful to not cause any damage. A famous example is an old (very old) vulnerability in Cisco routers where an empty UDP packet to port 500 caused the router to crash. Researchers should not go beyond a simple connection attempt (using valid payload) and a banner "grab". These scans should not attempt to log in, and rate-limiting has to be done carefully. In particular, if IP addresses are scanned sequentially, it may happen that several fo these IPs point to the same server.
Anything else you have seen researchers do that you liked or didn't like? There are more researchers than I listed here. I need to add more to the feed. Also, not all of them scan continuously, and the data I am showing here is only from yesterday.
---
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS Technology Institute
Twitter|


Comments